Network Annotation Propagation (NAP)
Network Annotation Propagation Overview¶
Network Annotation Propagation (NAP) uses spectral networks to propagate information from spectral library matching, in order to improve in silico fragmentation candidate structure ranking. This workflow is currently in beta development stages so any feedback is welcome to improve analysis and usability. It is available here under 'NAP_CCMS' Workflow drop down menu.
Check out the full documentation.
NAP short hands on tutorial¶
The aim of this tutorial is to work as a guided tour through this documentation page and exploring the finding of Kang et al., (2018).
- Go to Structure database section, download the example in house database (two columns file), add the structure SN00230021 to the file and generate the formatted database. Make sure you use an excel like software and save as tab separated text file;
- Go to Running NAP section, open NAP input interface, make sure you are logged and run a job with example parameters present in the picture (including job id: '3b215c4b25594b9c85d92de547815c0a' and cluster index: 56), with the database you just created. Go here if need instructions to upload the database;
- When your job is processed, you should receive a link similar to that. Go to section Online Exploration and browse the results;
- Follow the same link above. Go to section NAP Visualization in Cytoscape and browse the results;
Data Input Preparation¶
The following inputs are used for NAP:
- Molecular network task id, see Molecular Networking (required)
- Identifier(s) of databases and/or user provided databases (required)
Structure database¶
There are basically three options for database structure selection:
- Input one or more databases, separated by ",". Available options are: GNPS, HMDB, SUPNAT, CHEBI, DRUGBANK and FooDB. Be aware that these databases are static and new changes on the source databases are not incorporated automatically.
- Input an in house generated database. See Molecular Networking documentation to learn how to use the drag and drop upload.
A standard format is required for the in house database. One can easily collect structures in the literature and format a tab separated files with SMILES strings and a character identifier of any kind, as the example database Right-click, and Save link as:

Having an in house collection, before the use in NAP, the user has to first format the database, using the following webserver:

After submission for conversion the user should receive an email with the link to download a file in the following format Right-click, and Save link as:

- The combination of the two databases above. NAP allows the combination of different databases, either through multiple database identifiers, or by the combination of identifiers and text file. While this feature allows flexibility, it is important narrow the search space for the system under study.
Running NAP¶
NAP Workflow Selection¶
From the main GNPS page, you can access NAP clicking the banner
and then selecting NAP in the corresponding description. You can also directly open clicking "here".
This will take you to the workflow input to start NAP. The image below shows an example of the most important parameters
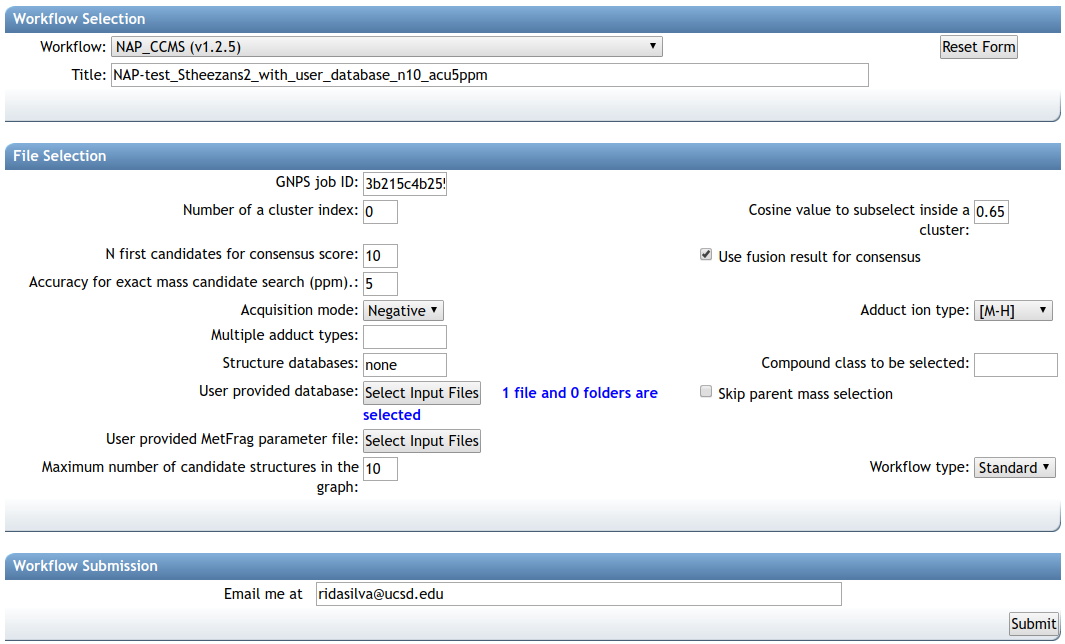
The first parameter is the GNPS network task id, this id can be found in the results email sent by GNPS or in the url, as shown in the image below, the task id is '3b215c4b25594b9c85d92de547815c0a'
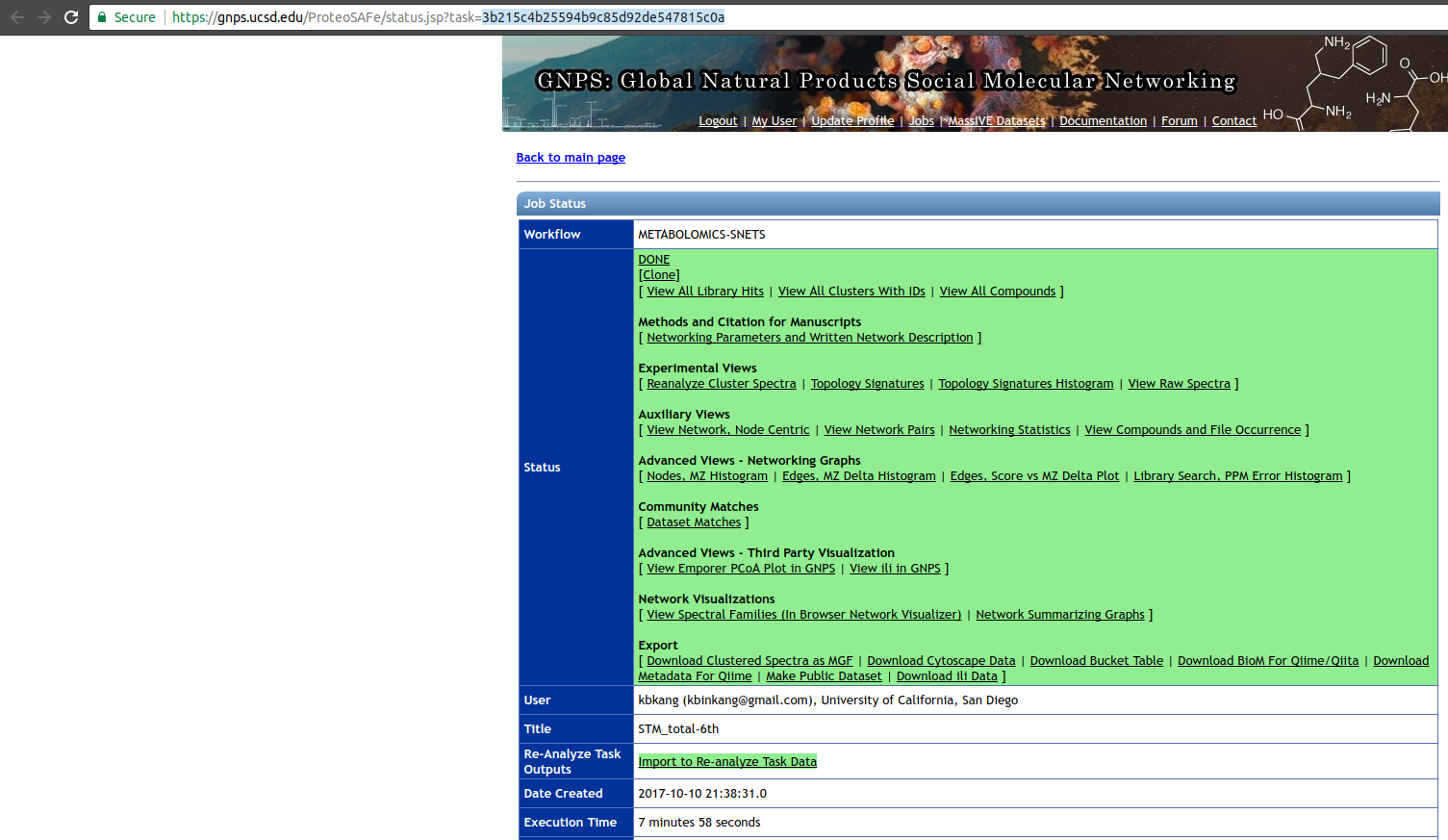
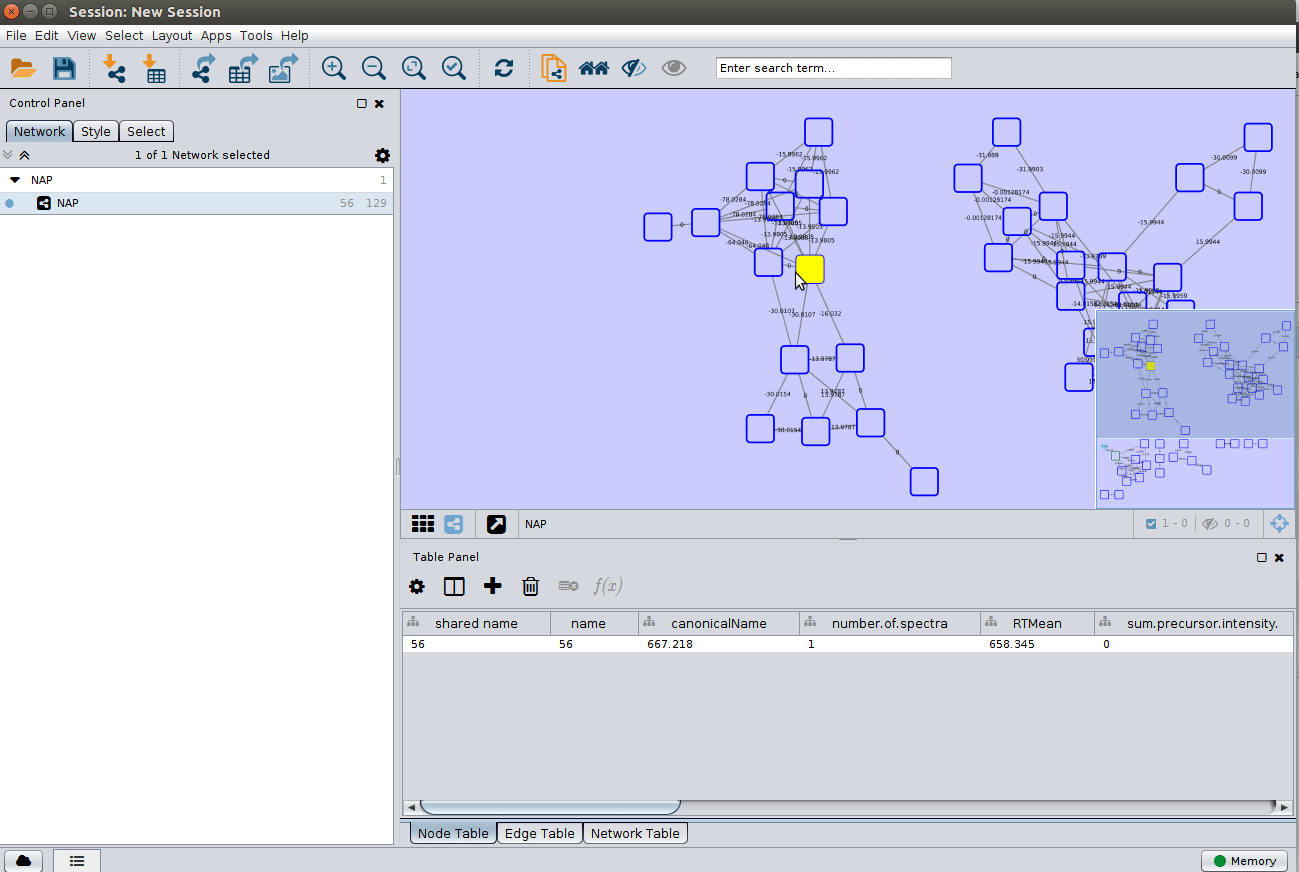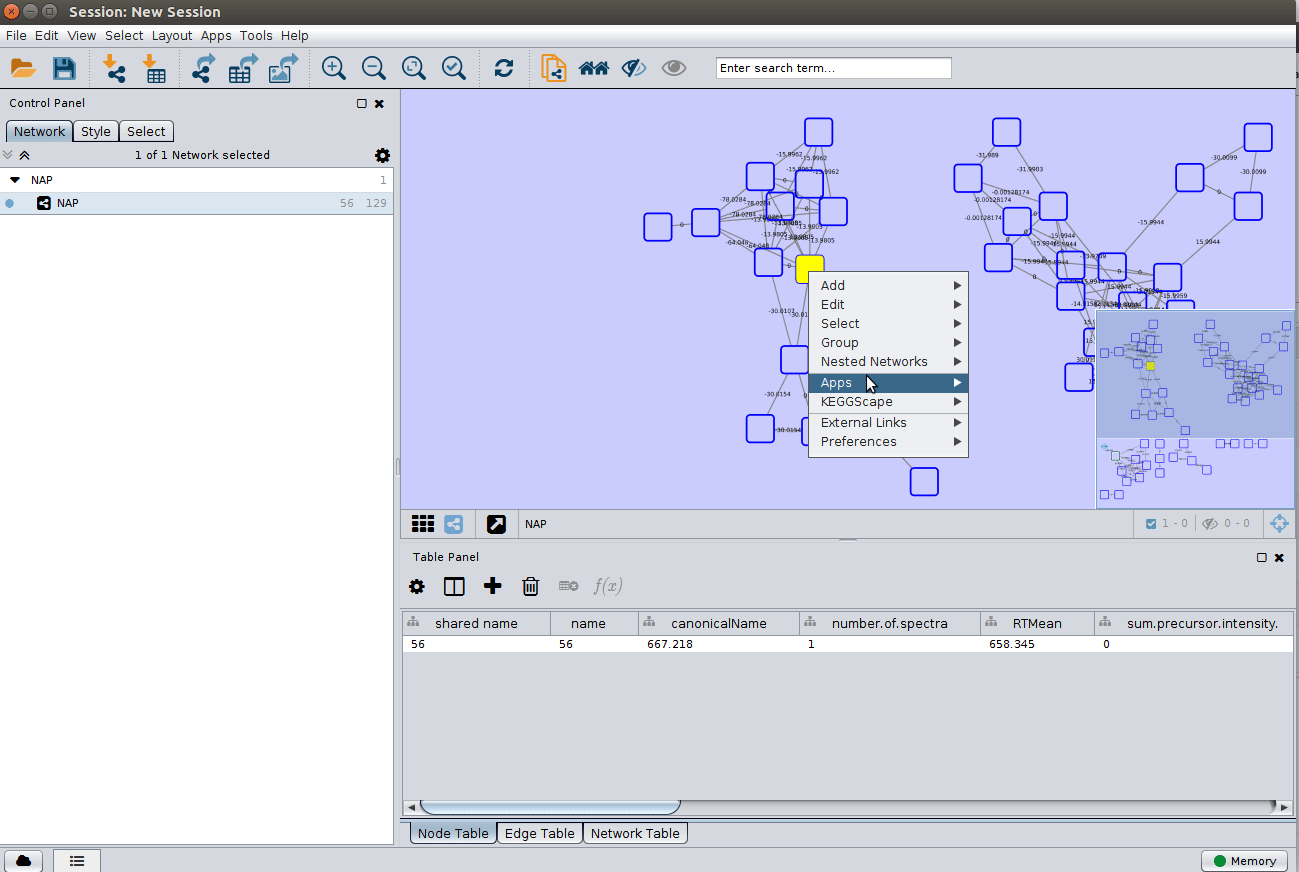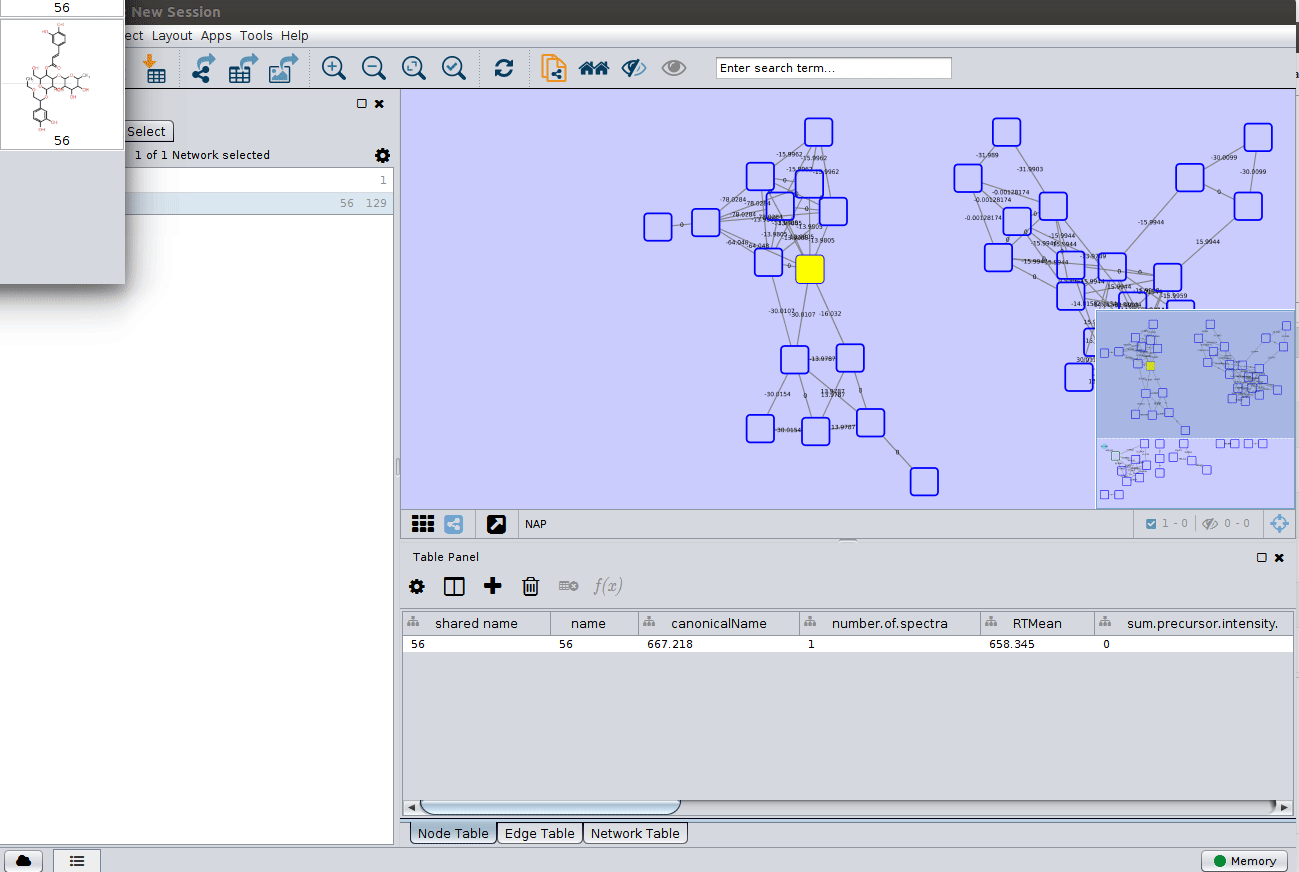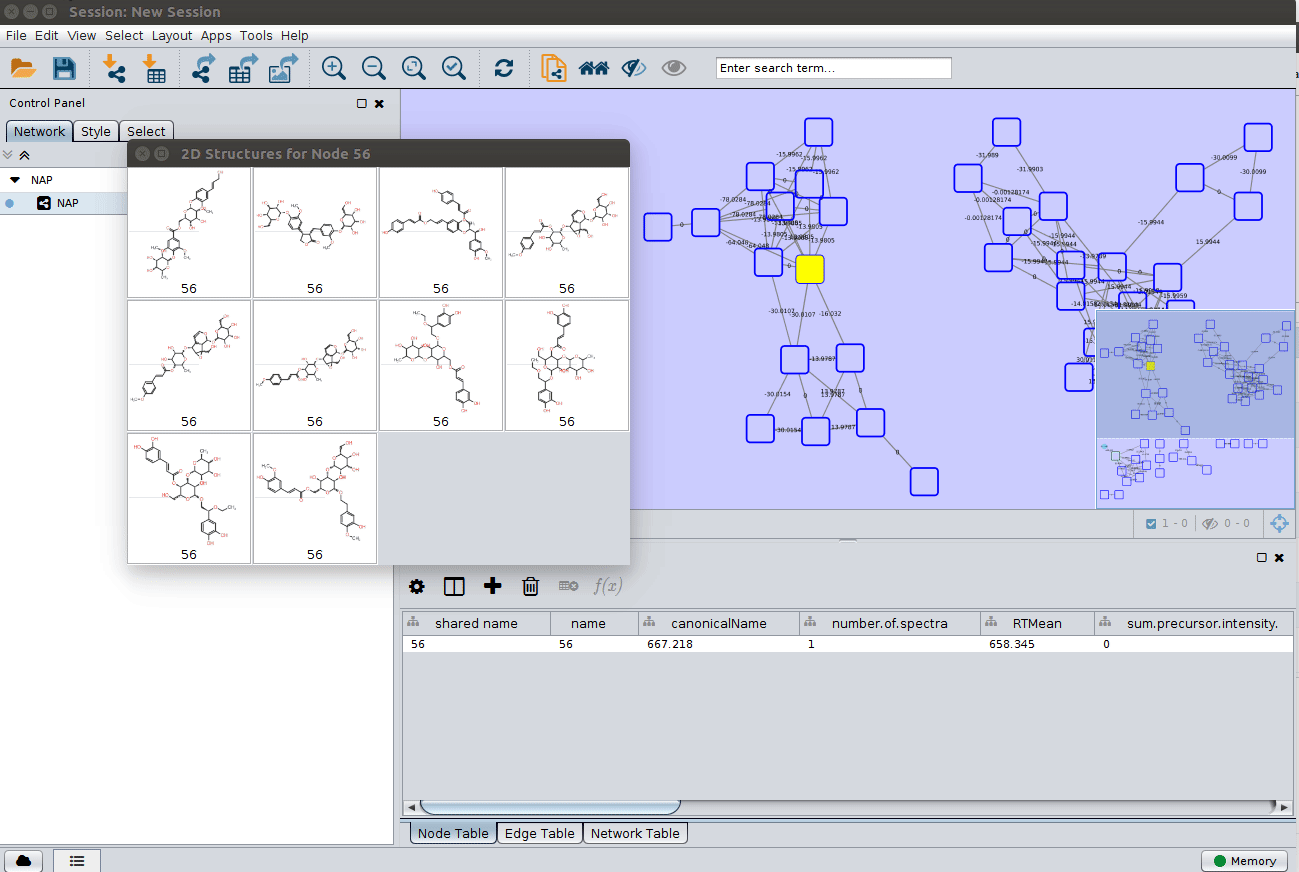
and the molecular family (connected component) containing the 'cluster index' 56 can be inspected in the molecular network.
A detailed description of the parameters is provided below.
Parameter Walkthrough¶
| Parameter | Description | Default |
|---|---|---|
| GNPS job ID | GNPS molecular networking task id. | |
| Number of a cluster index | Any cluster index of a connected component of interest in a Molecular Network. The propagation is limited by the connected component. | |
| Cosine value to subselect inside a cluster | Used to disconnect nodes in very dense molecular networks and decrease the number of nodes to be analyzed. | 0.5 |
| N first candidates for consensus score | Number of candidate structures of the neighbor nodes used for Consensus re-ranking. | 10 |
| Use fusion result for consensus | Whether to use the result from Fusion re-ranking to perform Consensus re-ranking. | 1 |
| Accuracy for exact mass candidate search (ppm) | Accuracy used for structure database search. The predicted neutral mass (for a given adduct selected) is compared to the exact mass of the structures provided. | 15 |
| Acquisition mode | Mass spectrometry acquisition mode. | Positive |
| Adduct ion type | Expected adduct type for the precursor ion mass. | [M+H] |
| Multiple adduct types | Input one or more adducts, separated by ",". Available options are: listed on the Adduct drop down menu. | |
| Structure databases | Input one or more databases, separated by ",". Available options are: GNPS, HMDB, SUPNAT, CHEBI, DRUGBANK and FooDB. Use none to select only user defined. | |
| Compound class to be selected | ClassyFire class in the following format: "class:name". | |
| User provided database | In house candidate structure database to be used in the search. | |
| Skip parent mass selection | Should be used only in combination with class selection. | 0 |
| User provided MetFrag parameter file | Check here for a template. | |
| Maximum number of candidate structures in the graph: | Number od candidate structures to be exported in the Cytoscape graph. | 10 |
| Workflow type | Standard or MZmine. |
Online Exploration of NAP results¶
After completing a NAP workflow, the results can be browsed in the web interface. The web interface provides a quick and easy way to perform initial analysis of your data, particularly if you are interested in a specific structure or class of structures and want to inspect in the results.
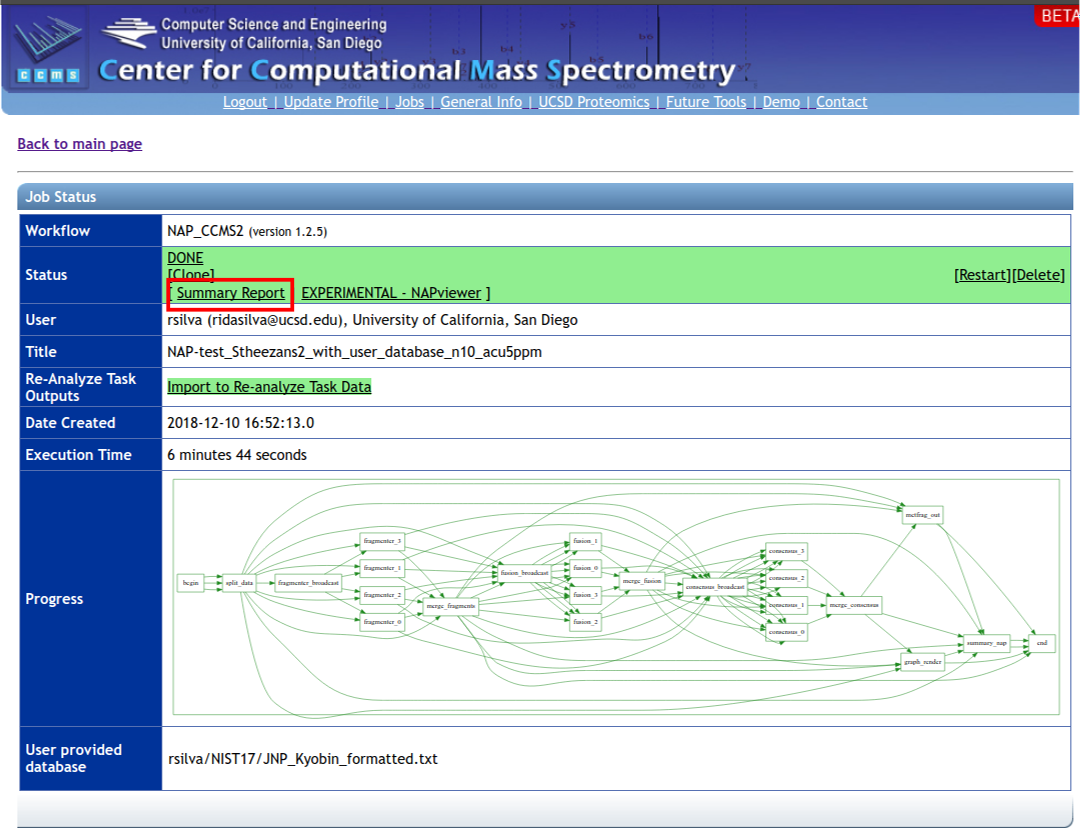
To have access to the web interface click on the 'EXPERIMENTAL - NAPviewer' at the results page:
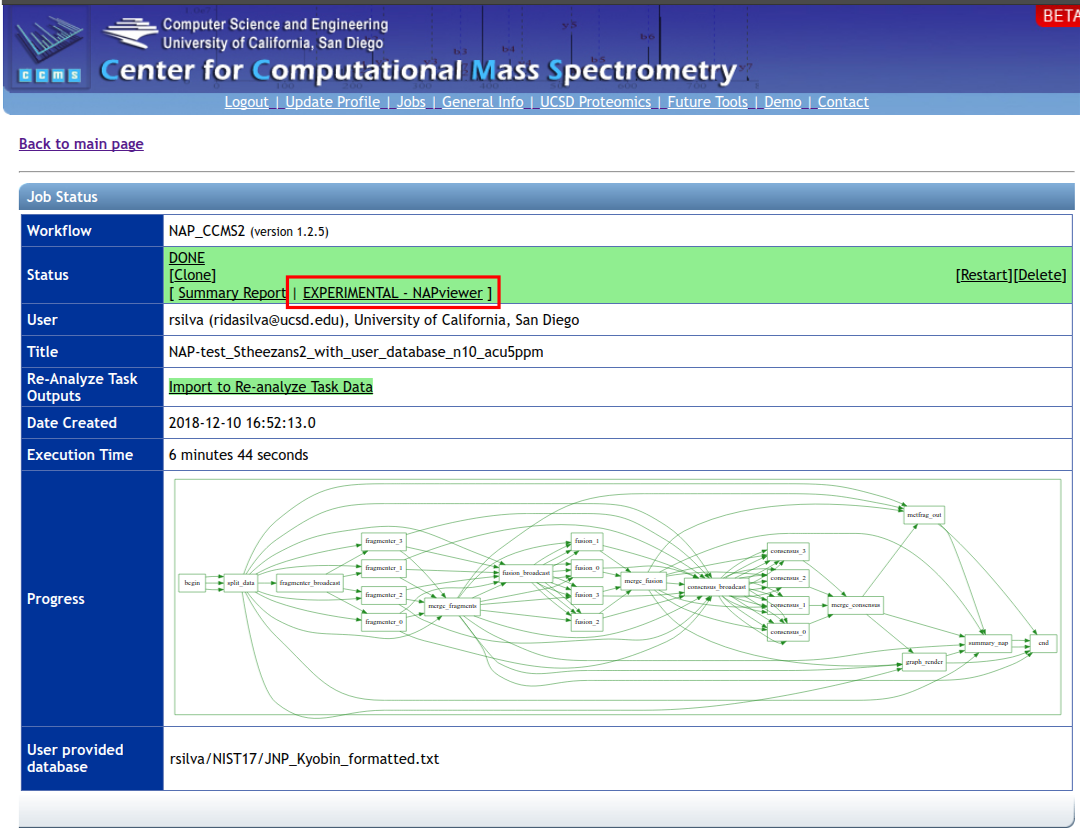
The result summaries can be divided in four sections.
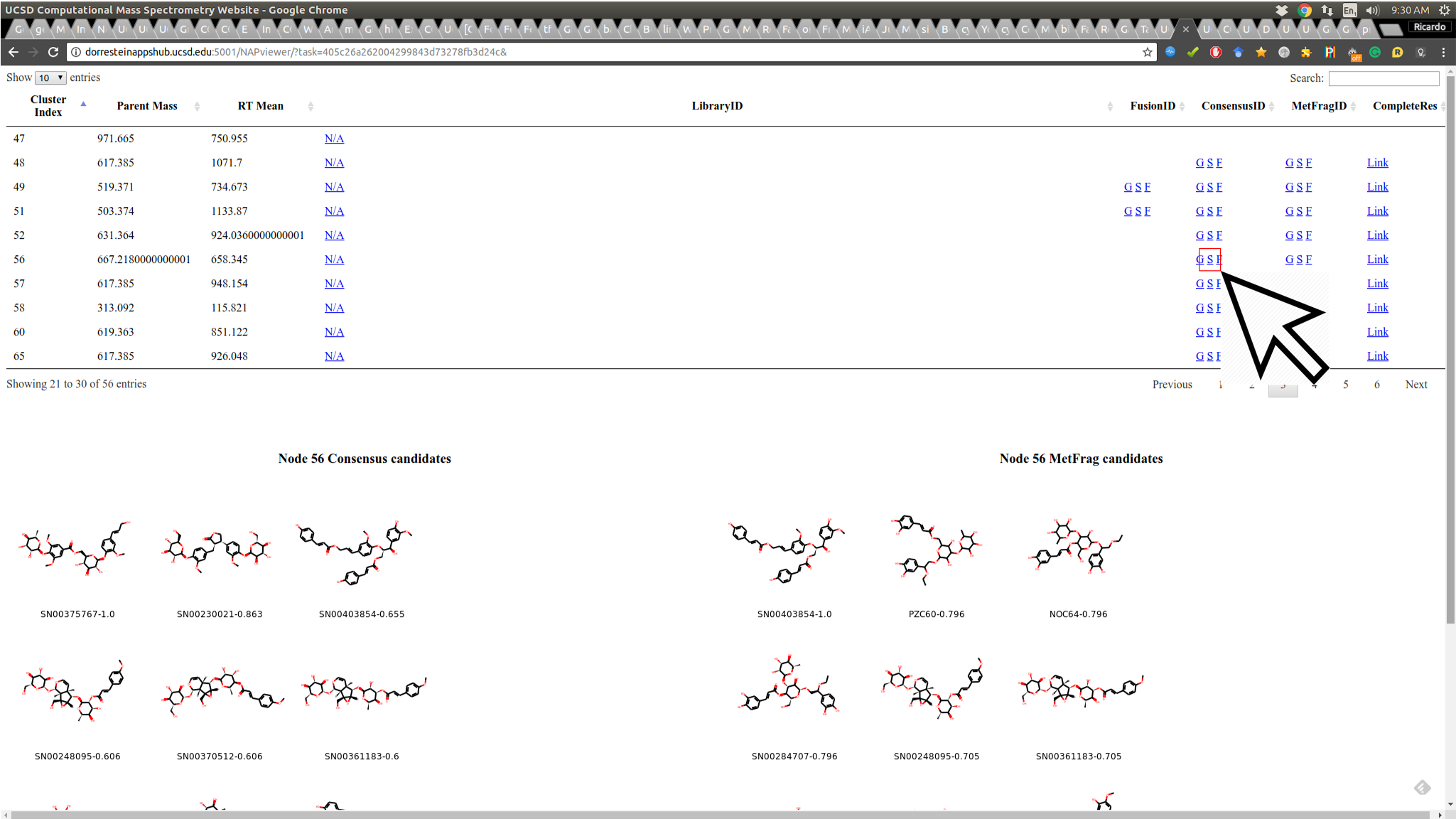
1. Structure view¶
NAP attempts to re-rank the candidate structures provided by MetFrag using the information provided by the molecular network. This first view shows the Structures ranked by MetFrag and the ones re-ranked by NAP to allow the user to quickly inspect if the propagation improved the ranking:
2. Graph view¶
As the re-ranking is performing obtaining information from neighbor nodes, the Graph view displays the direct neighbor's first candidate structures of a given re-ranked node to allow the user to inspect if the re-ranking is consistent in the network:
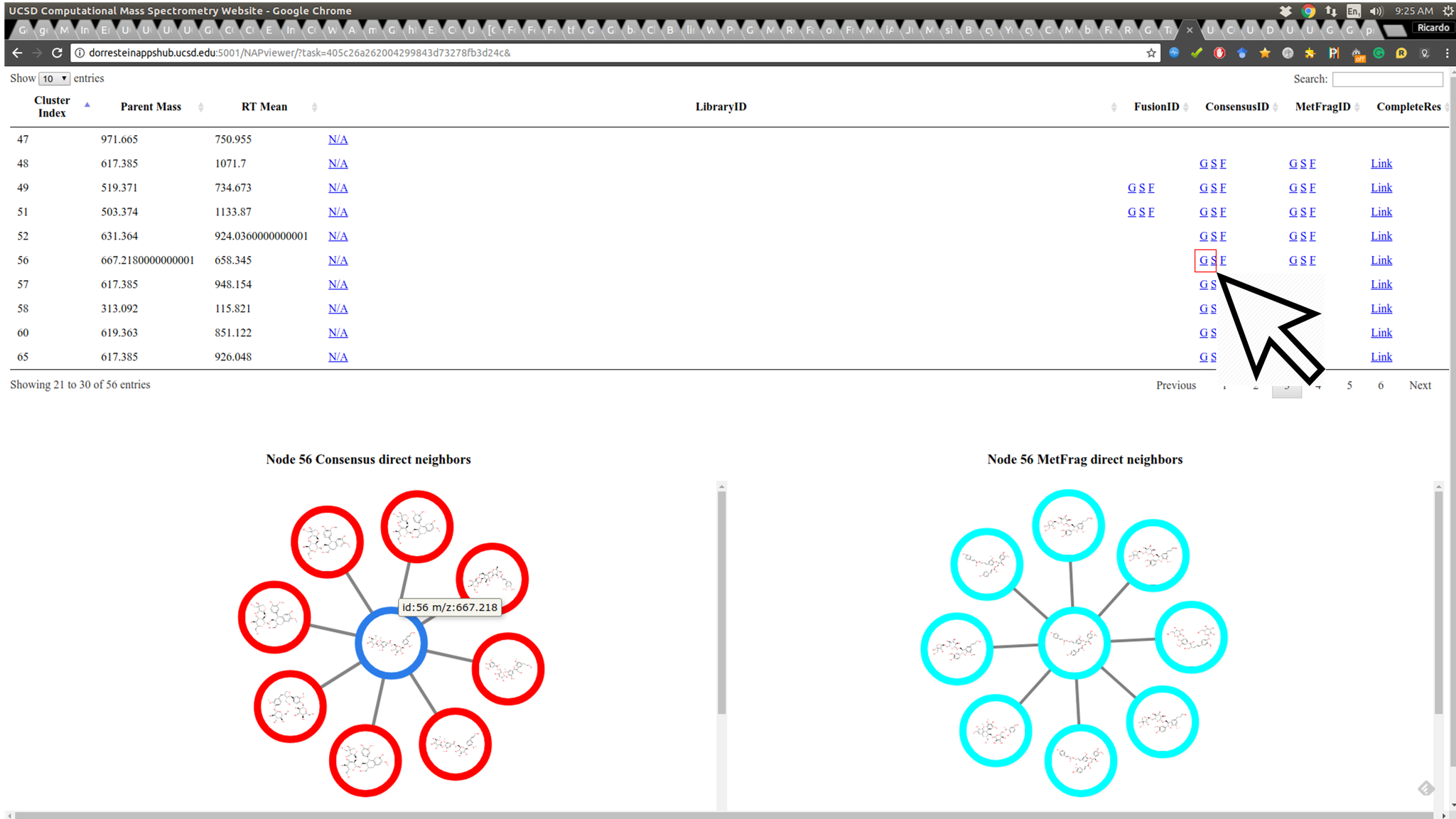
The node border colors indicate the source of structure: green - reference spectral library structure; magenta MetFrag's first candidate; blue Fusion's first candidate and red Consensus' first candidate.
3. Fragment view¶
Some important aspects of structural prediction are: how many fragments were predicted, which fragments and which substructures were assigned to the predictions. The Fragment view displays the direct fragments predicted for each structure in the candidate list of a given fragmentation spectrum (represented by a node in the network):
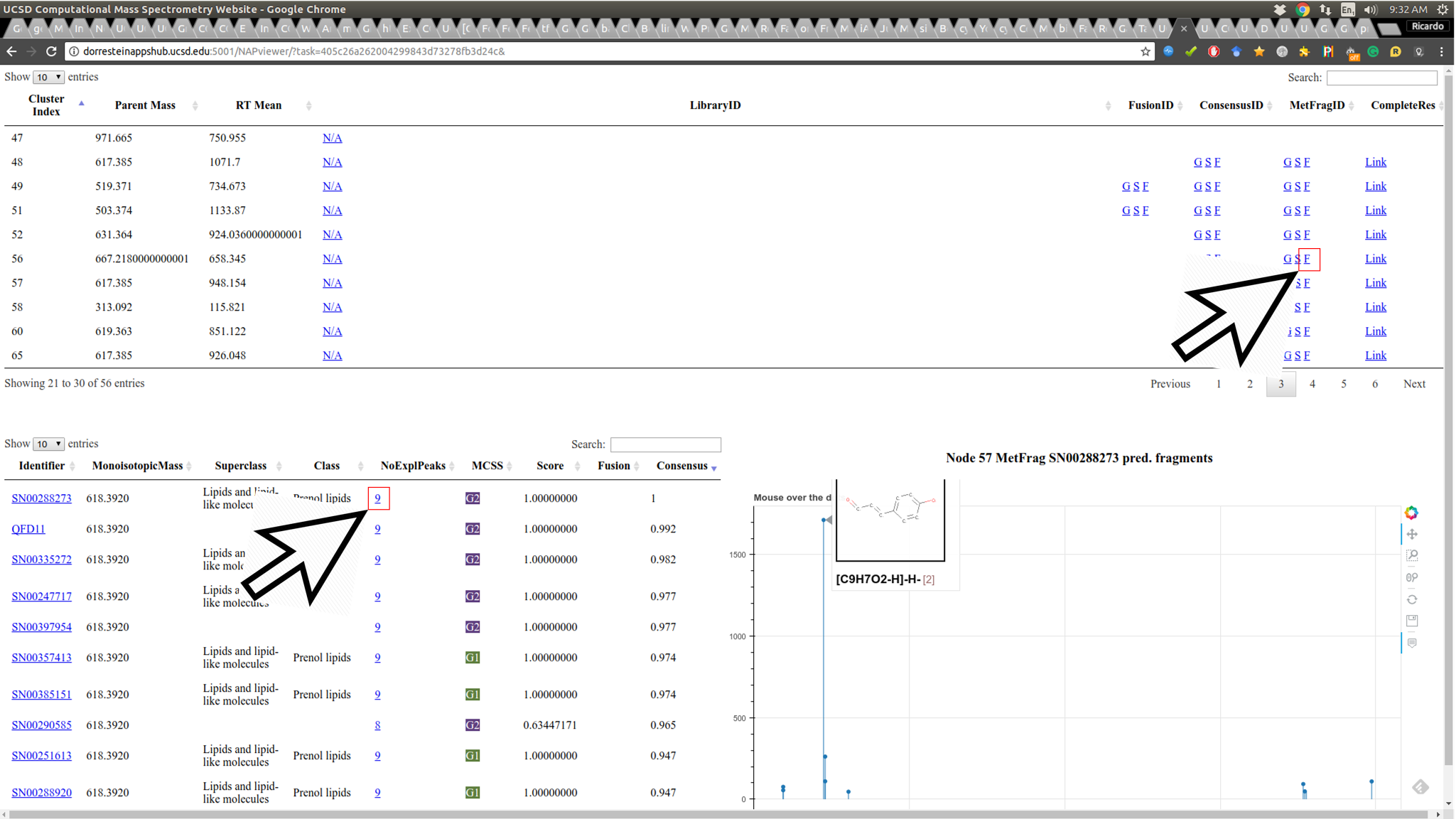
By hovering the mouse over the candidate fragment it is possible to see the substructure predicted for the fragment.
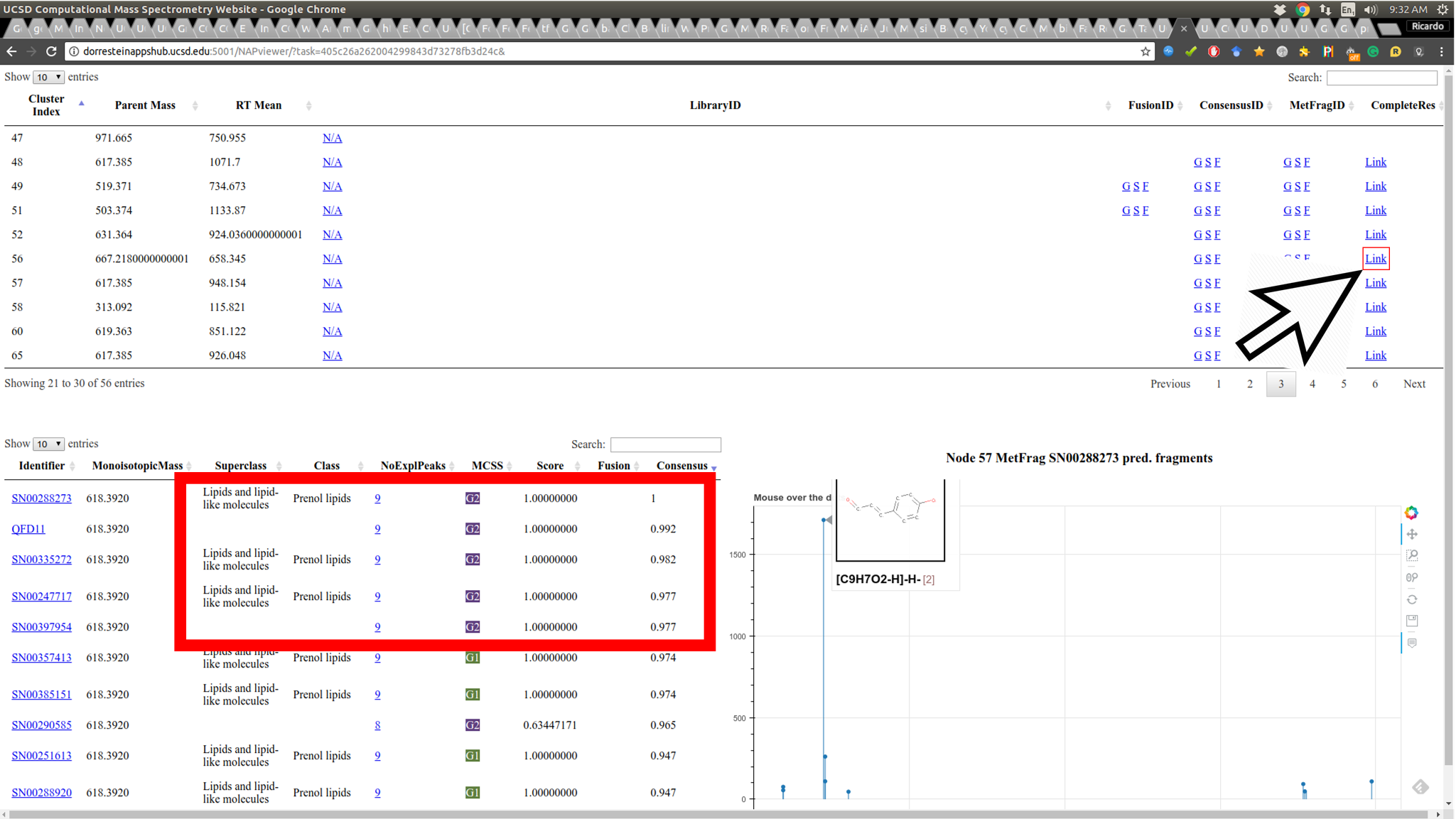
4. Full candidate list view¶
As structural prediction is very challenging. The correct candidate may not be the first in the list, therefore it is important to be able to browse the candidate list. The Link containing the full list of candidate structures found in NAP search is provided. The first column of the candidate's table contains a link out for the respective database where the structure was originated. The table also contains the ranking for MetFrag, Fusion and Consensus, the link for number of fragments predicted for each candidate structure, a link to fragment plot representation and a column with color coded structural similarity grouping that can be easily associated with candidate's ClassyFire class, when available:
NAP Visualization in Cytoscape¶
In a similar way as Molecular Networking uses Cytoscape to visualize the whole network, we can visualize structure prediction of entire connected component or networks using the output from NAP.
Cytoscape (we have used version >= 3.4) is available for download from here.
Download NAP Cytoscape files¶
To download NAP's Cytoscape file, go back to the results page of your task:
and download the compacted file containing the 'structure_graph_alt.xgmml' file.
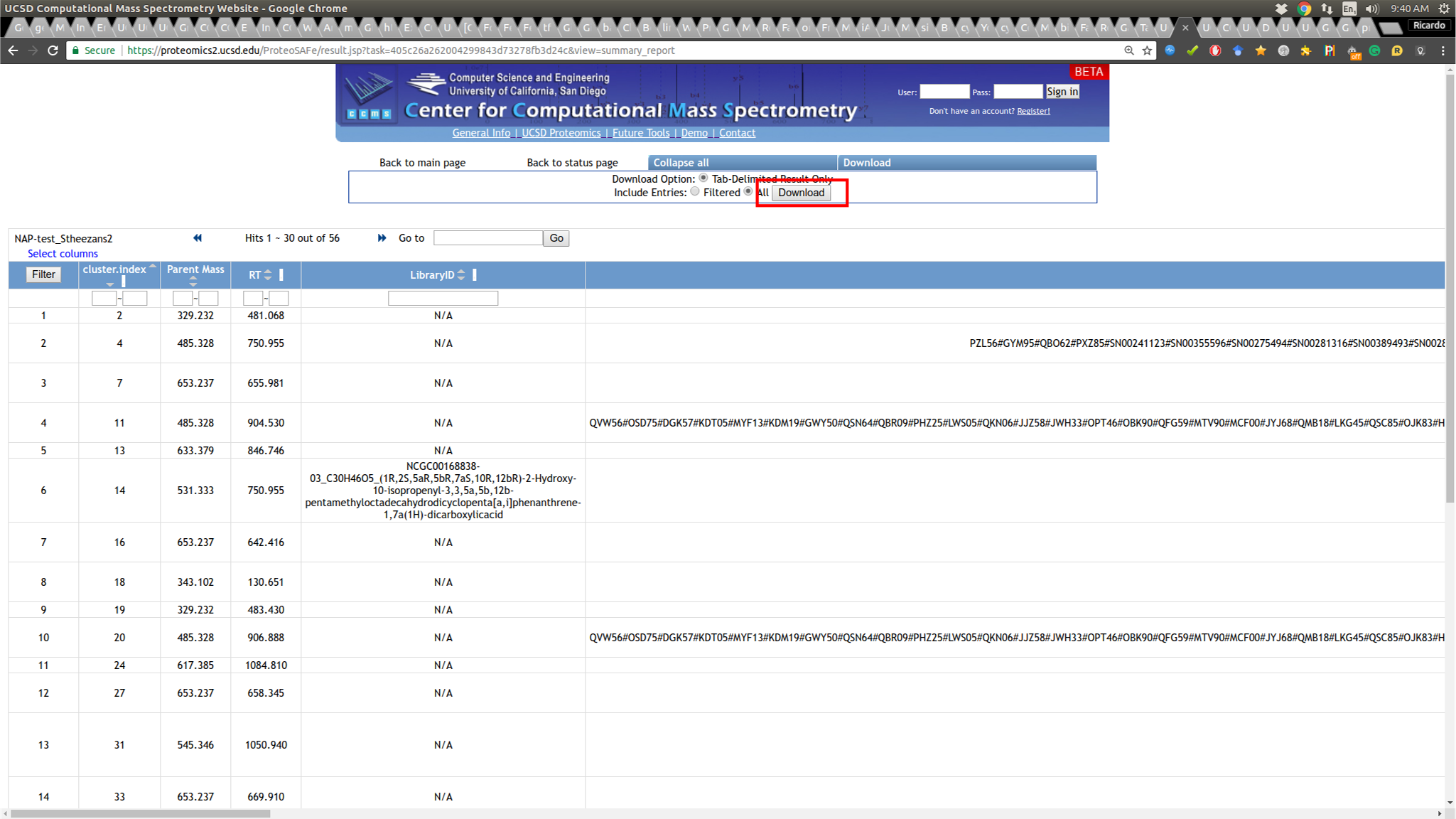
After the download, remember to uncompress the file for downstream use.
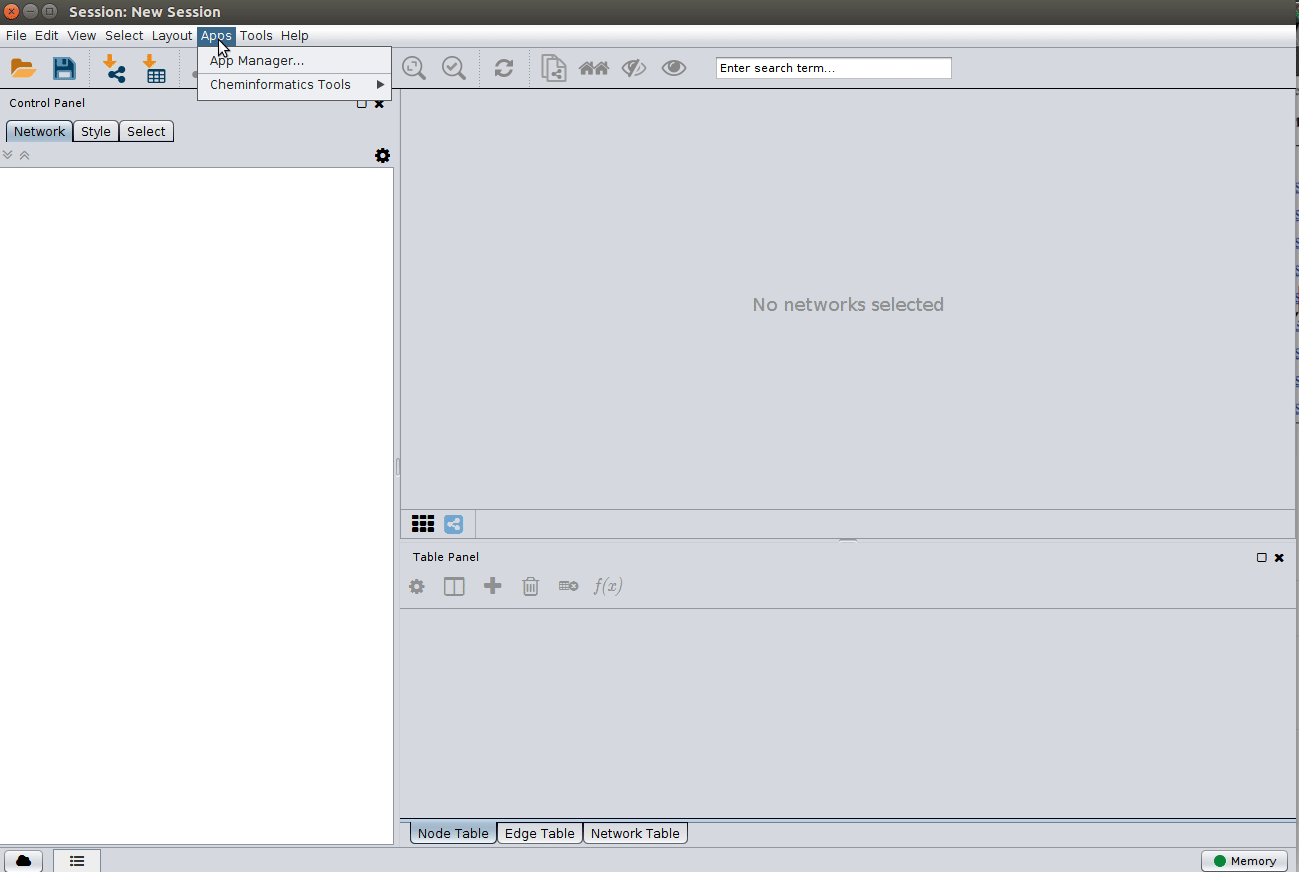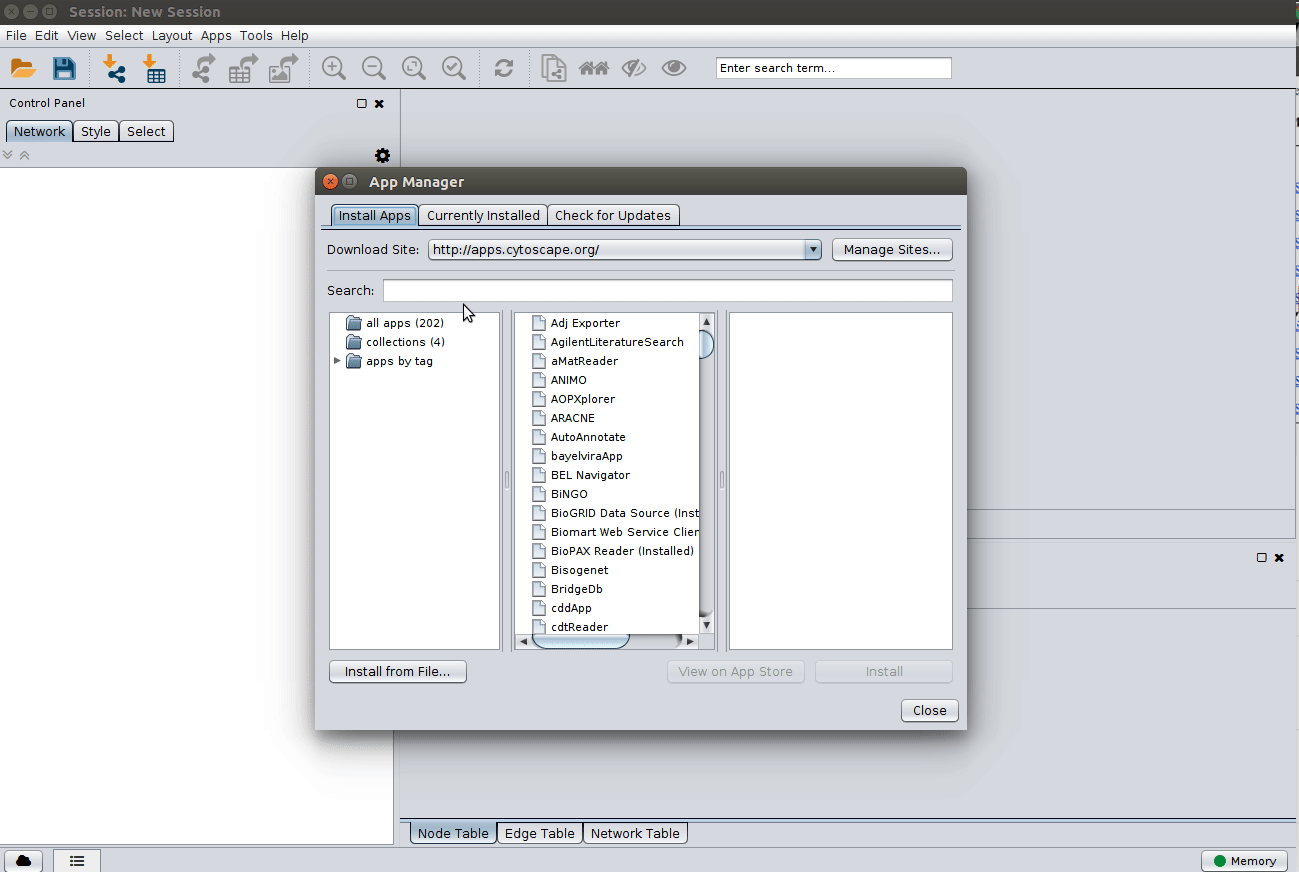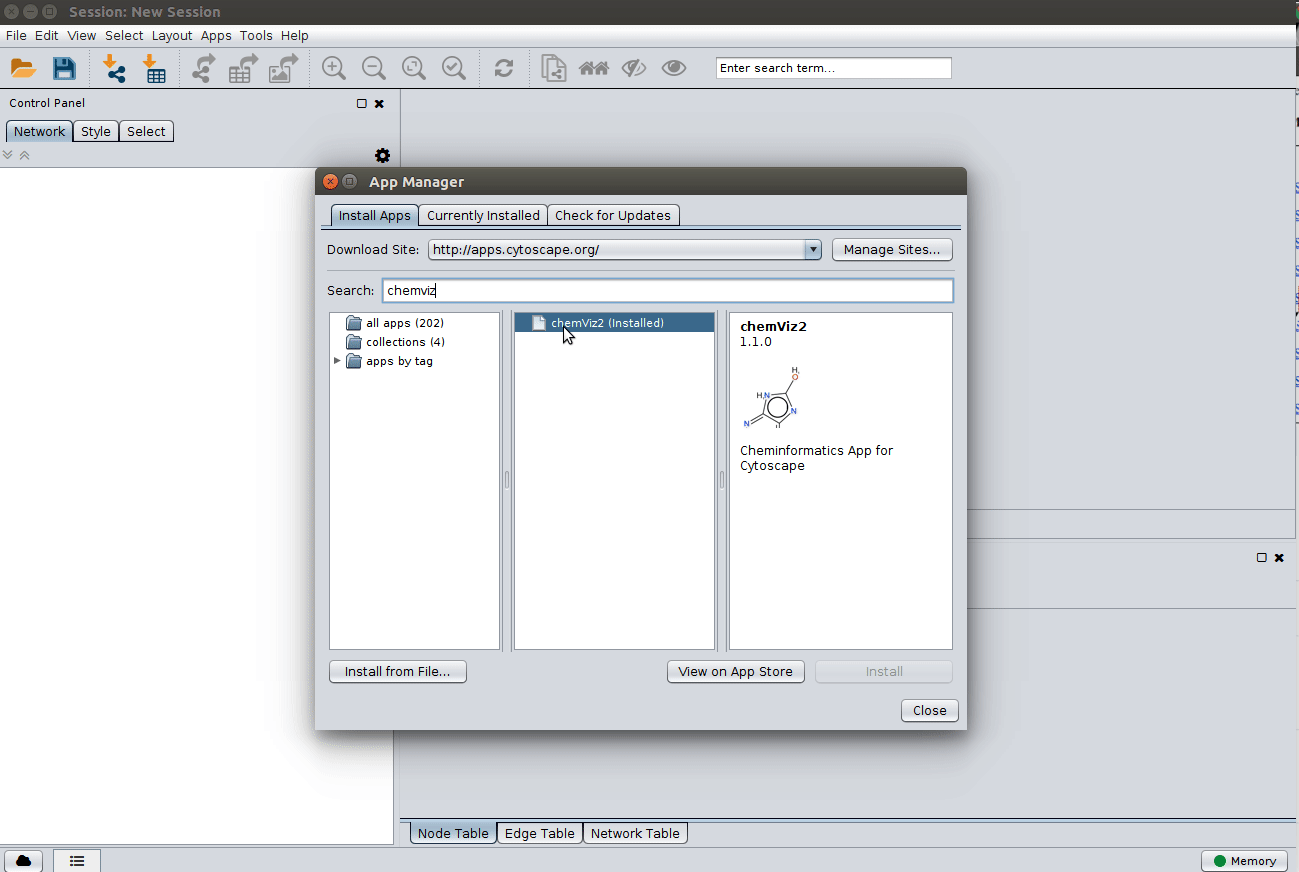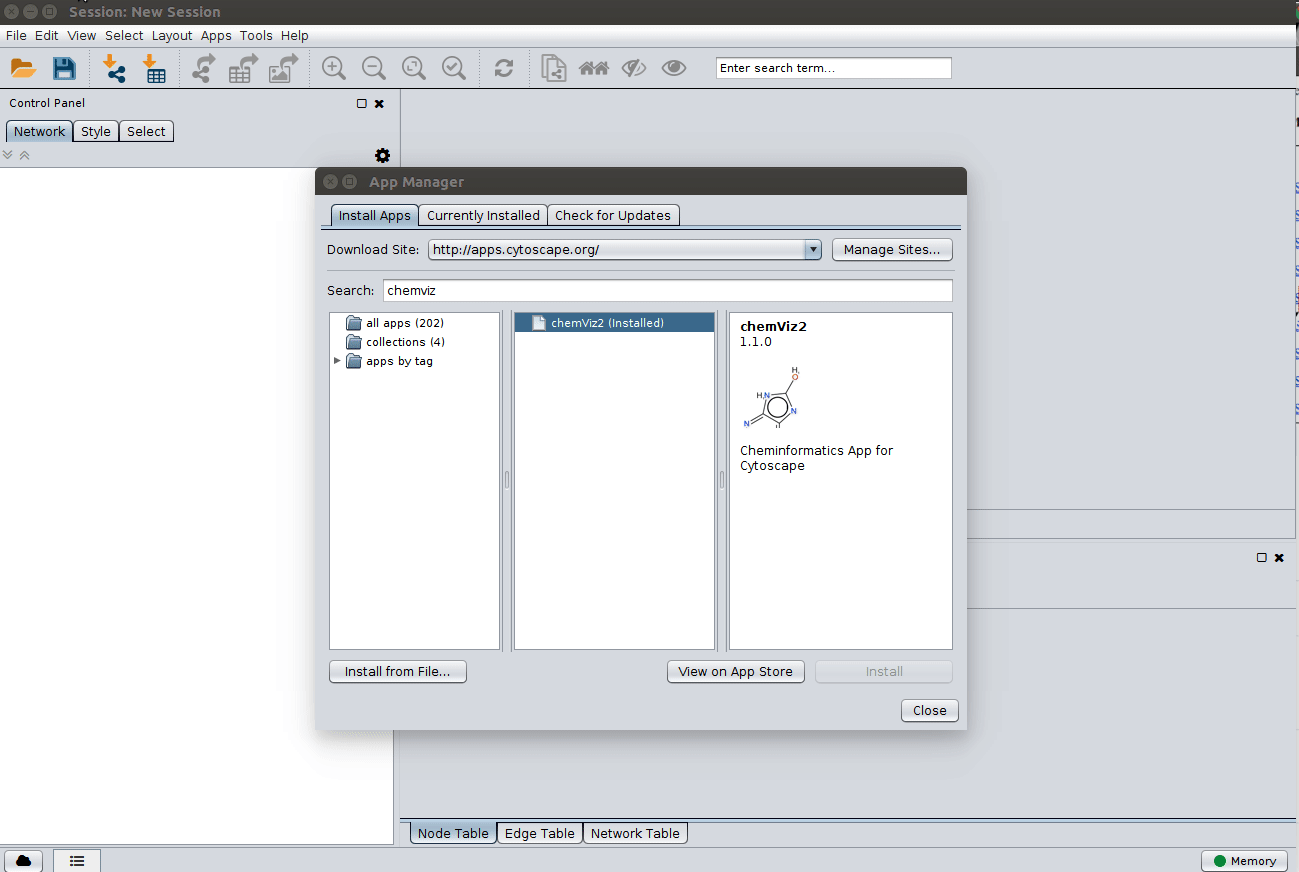
Installing the ChemViz plugin¶
To visualize the structures on NAP output we need the ChemViz plugin. The easiest way to install it is using Cytoscape's App Manager, as shown below:
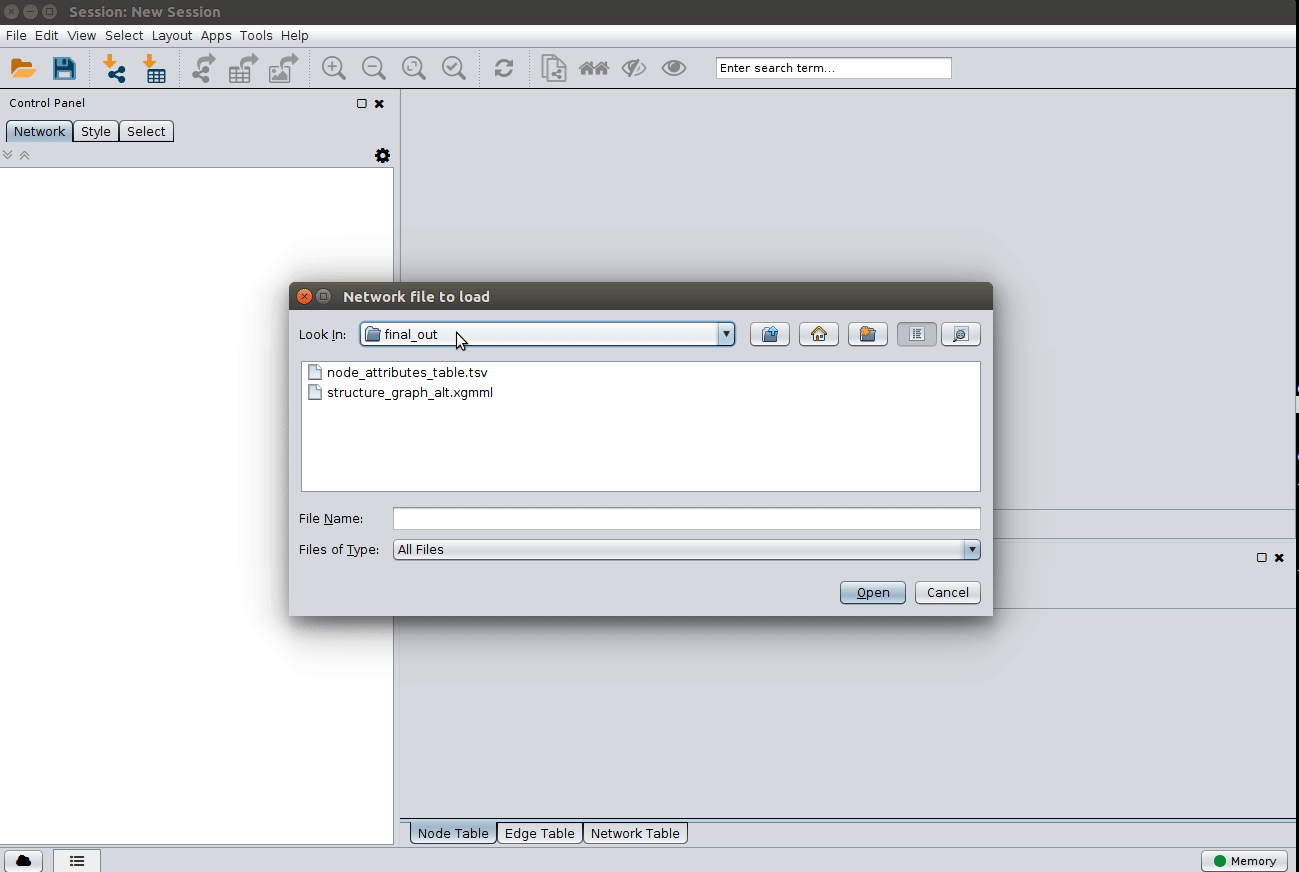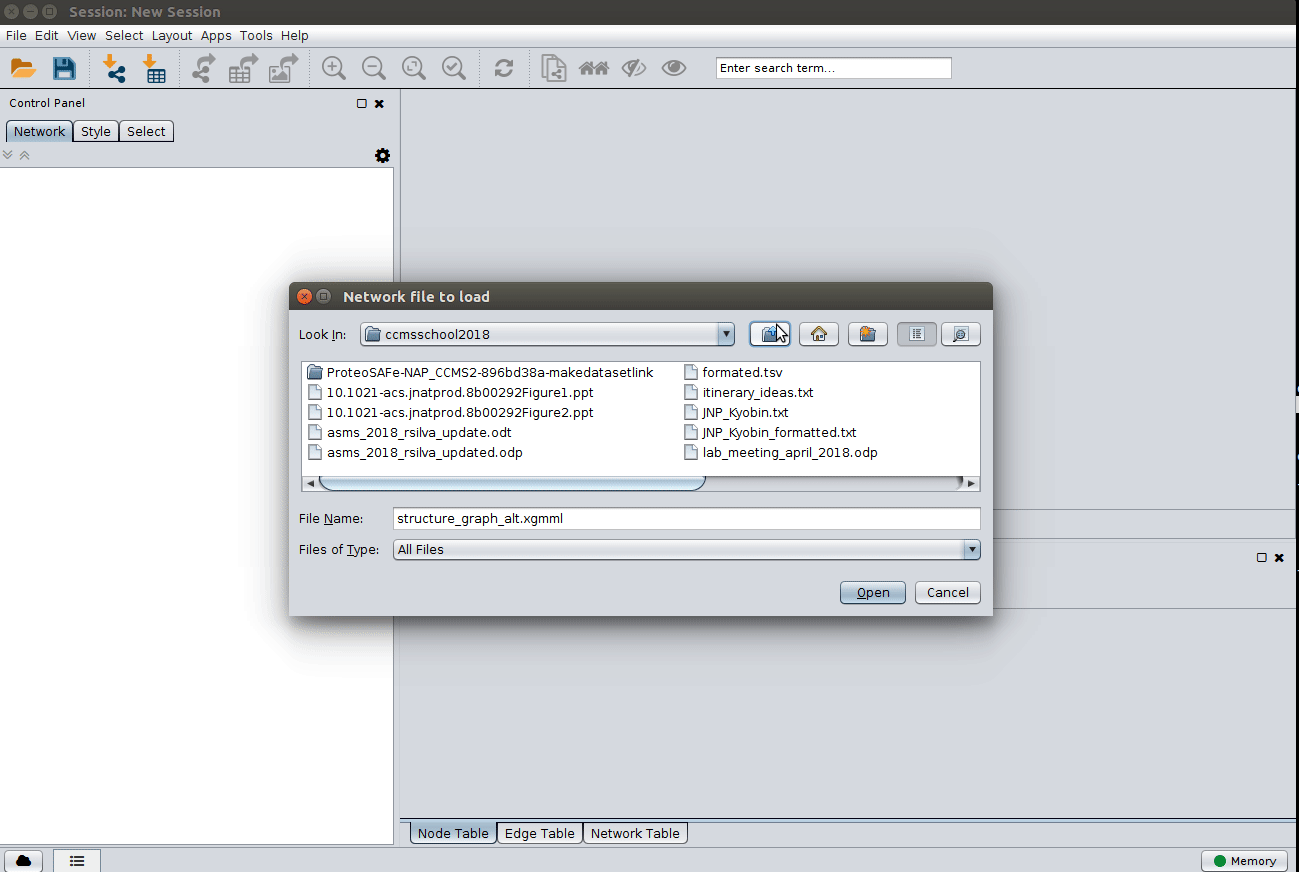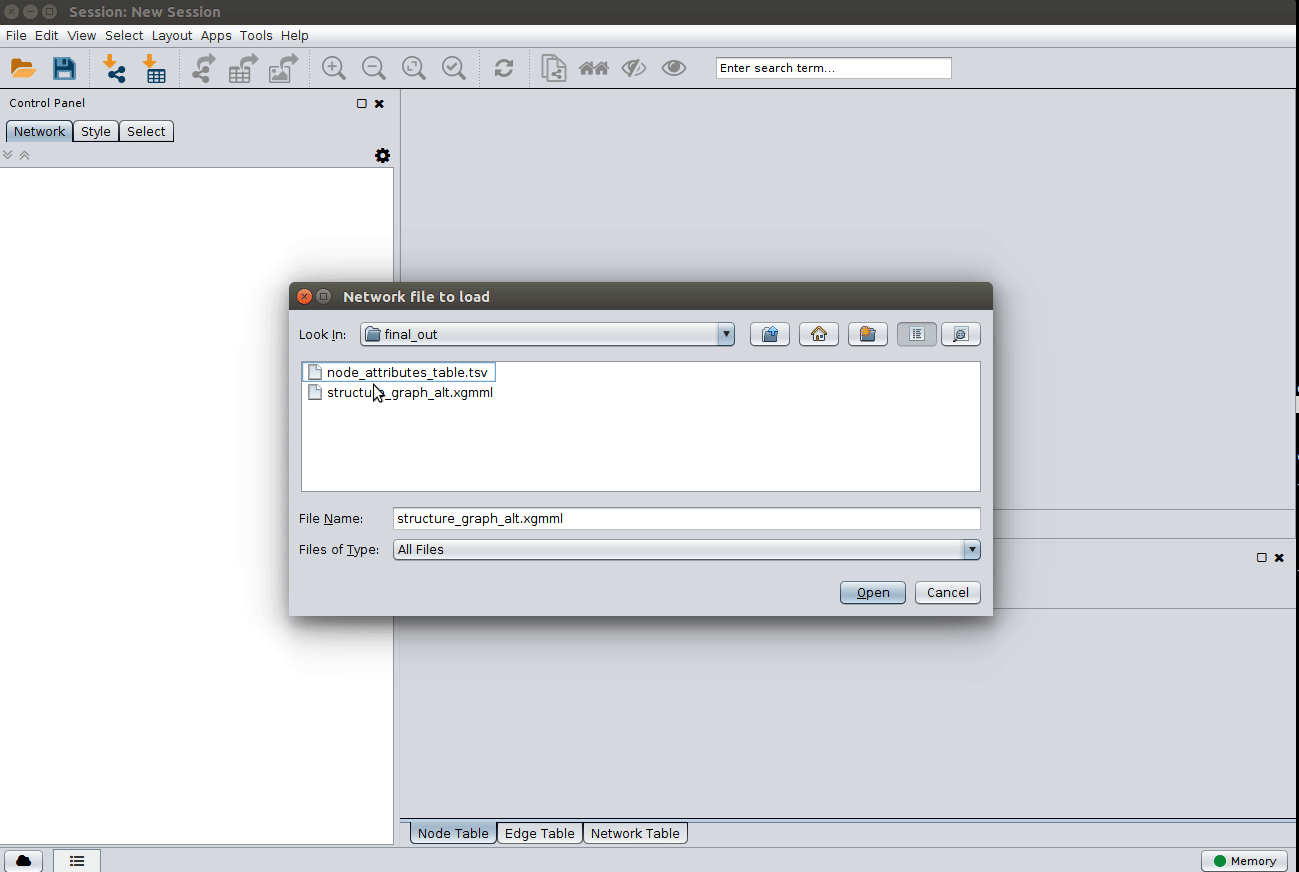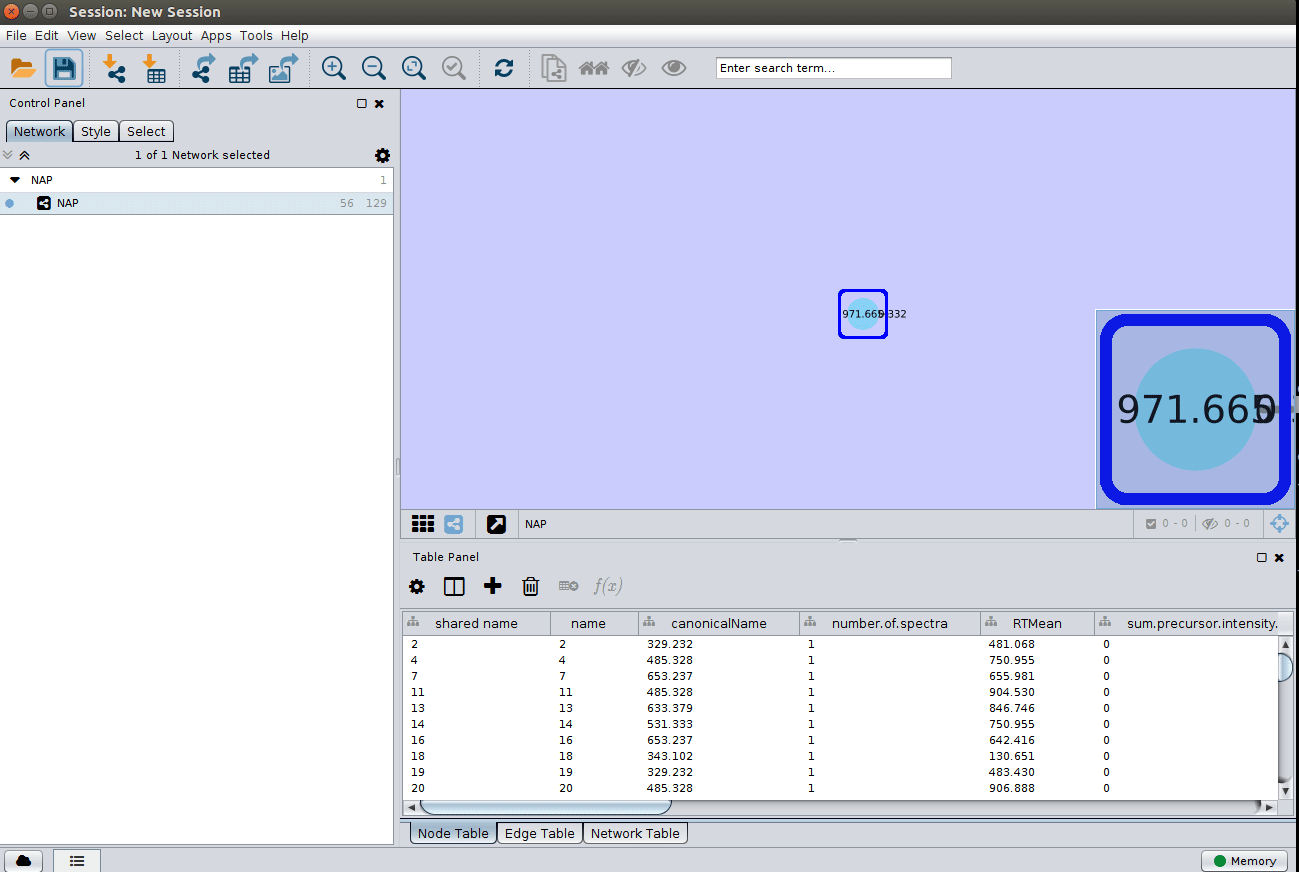
Load NAP Cytoscape file and apply layout¶
Load the 'structure_graph_alt.xgmml' file:
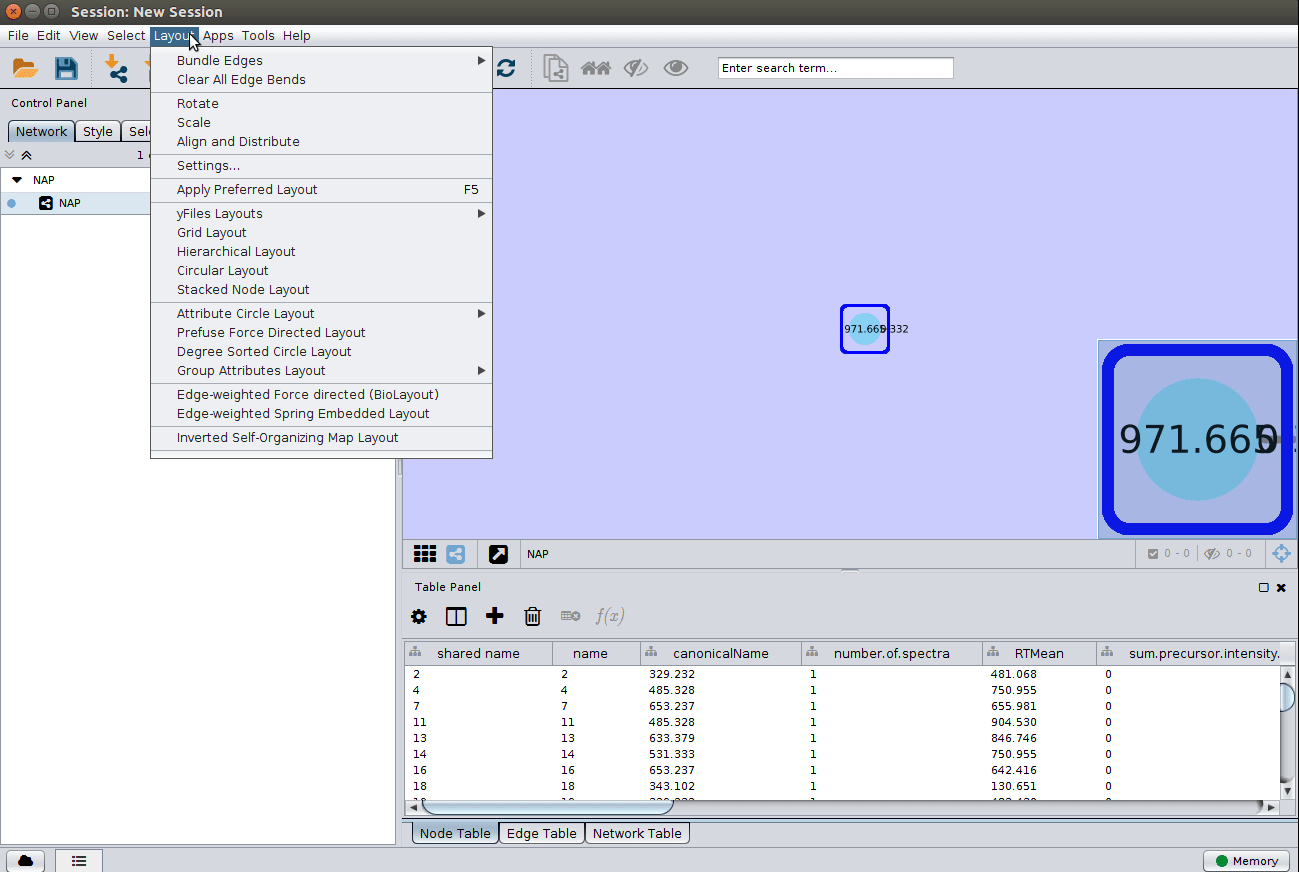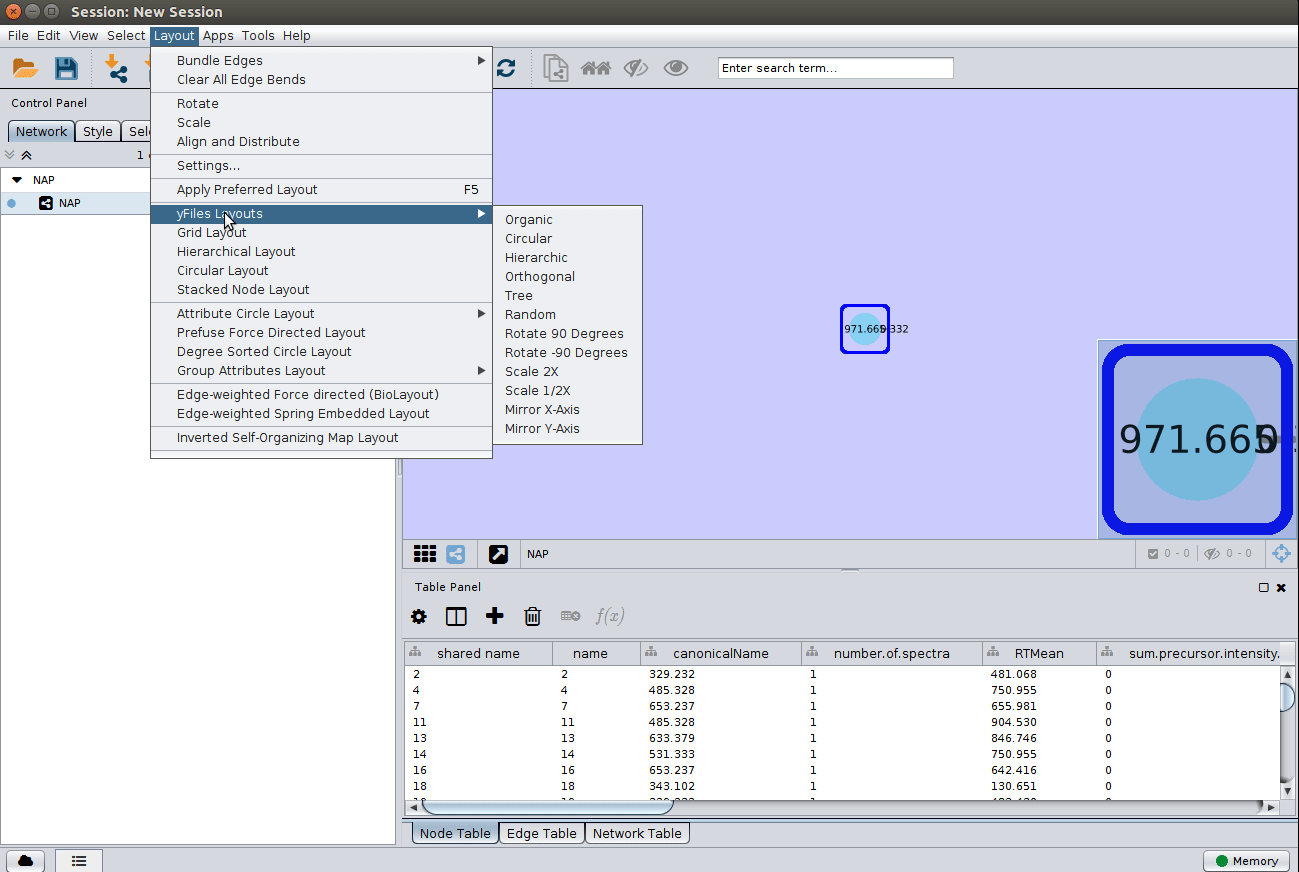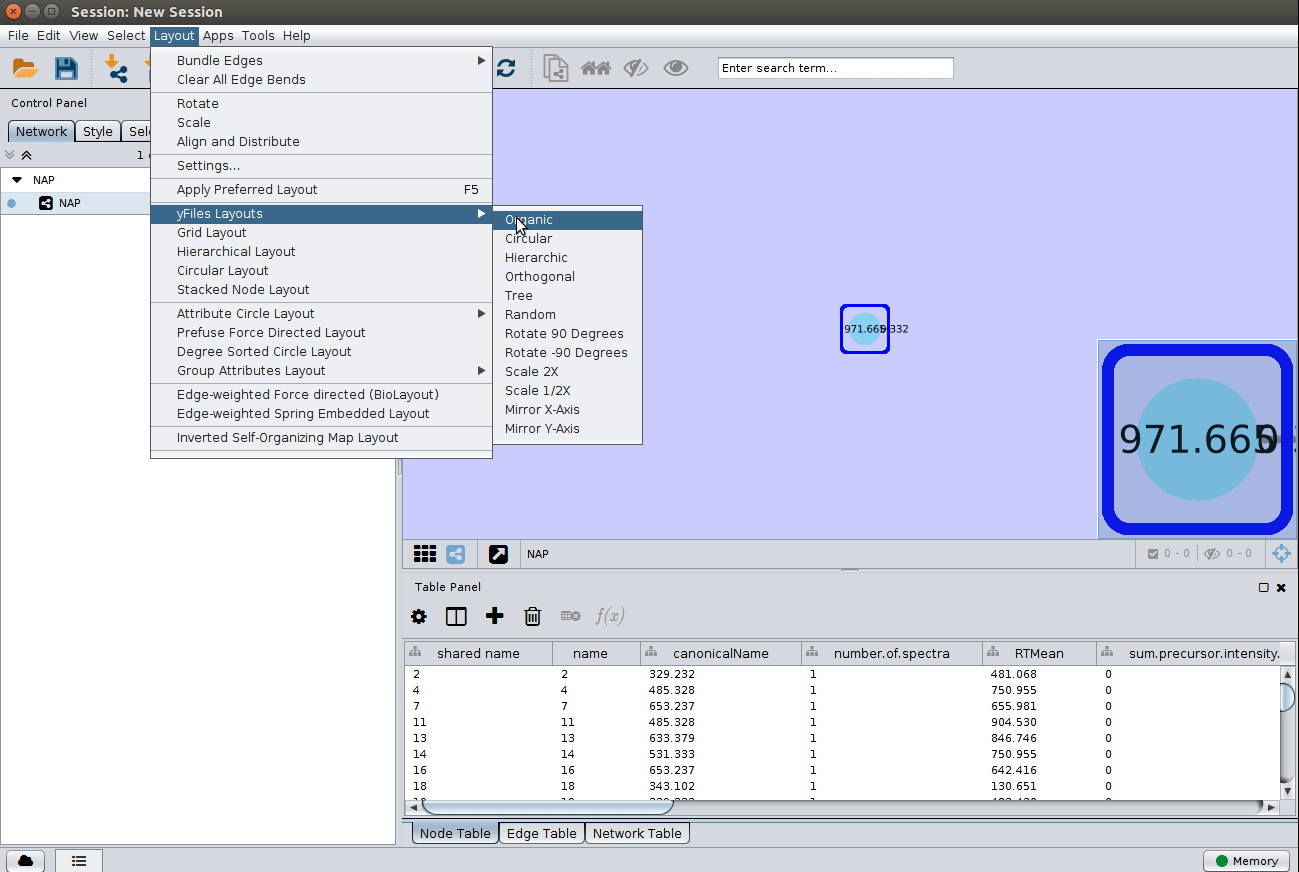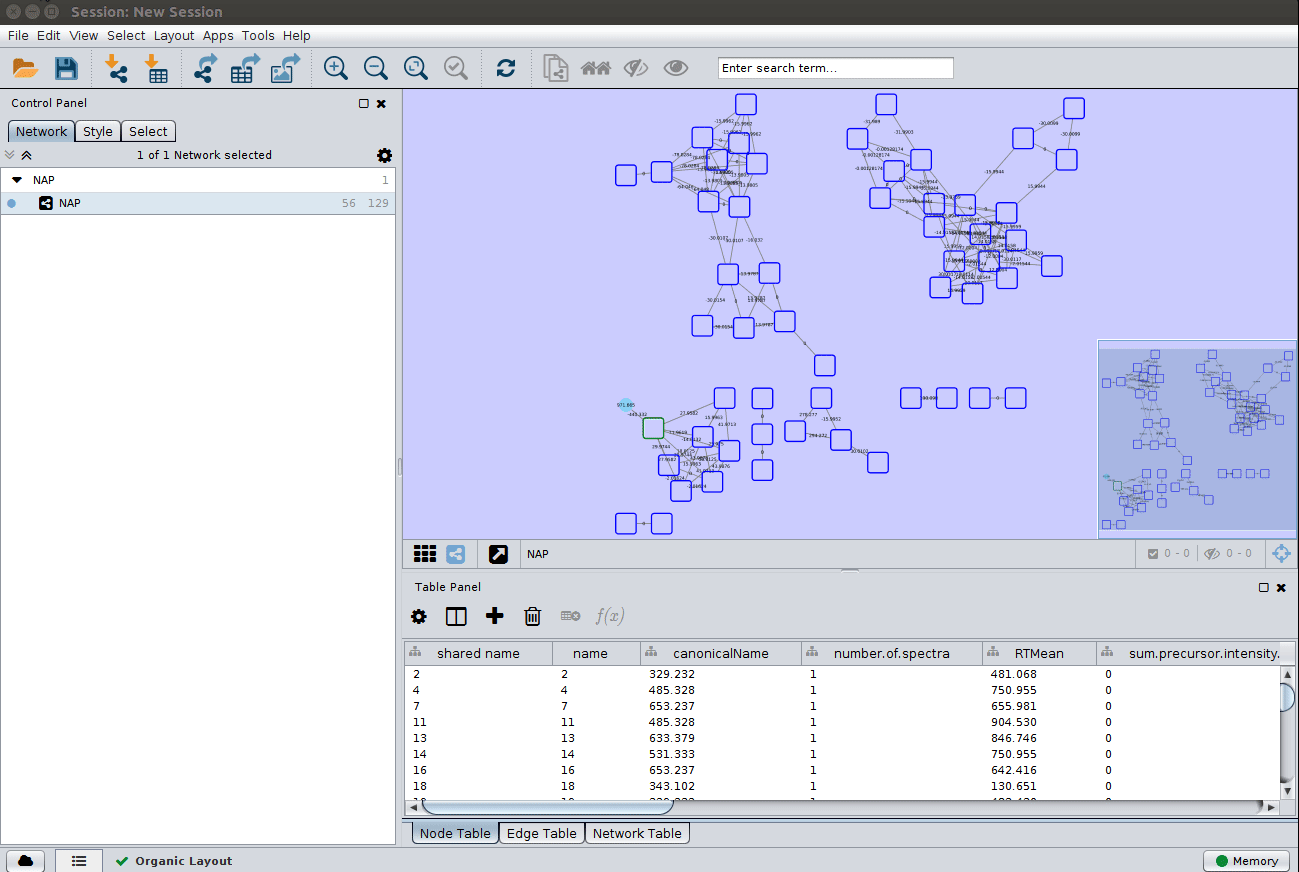
and apply a layout to spread the nodes:
Change image display properties and paint library match structure¶
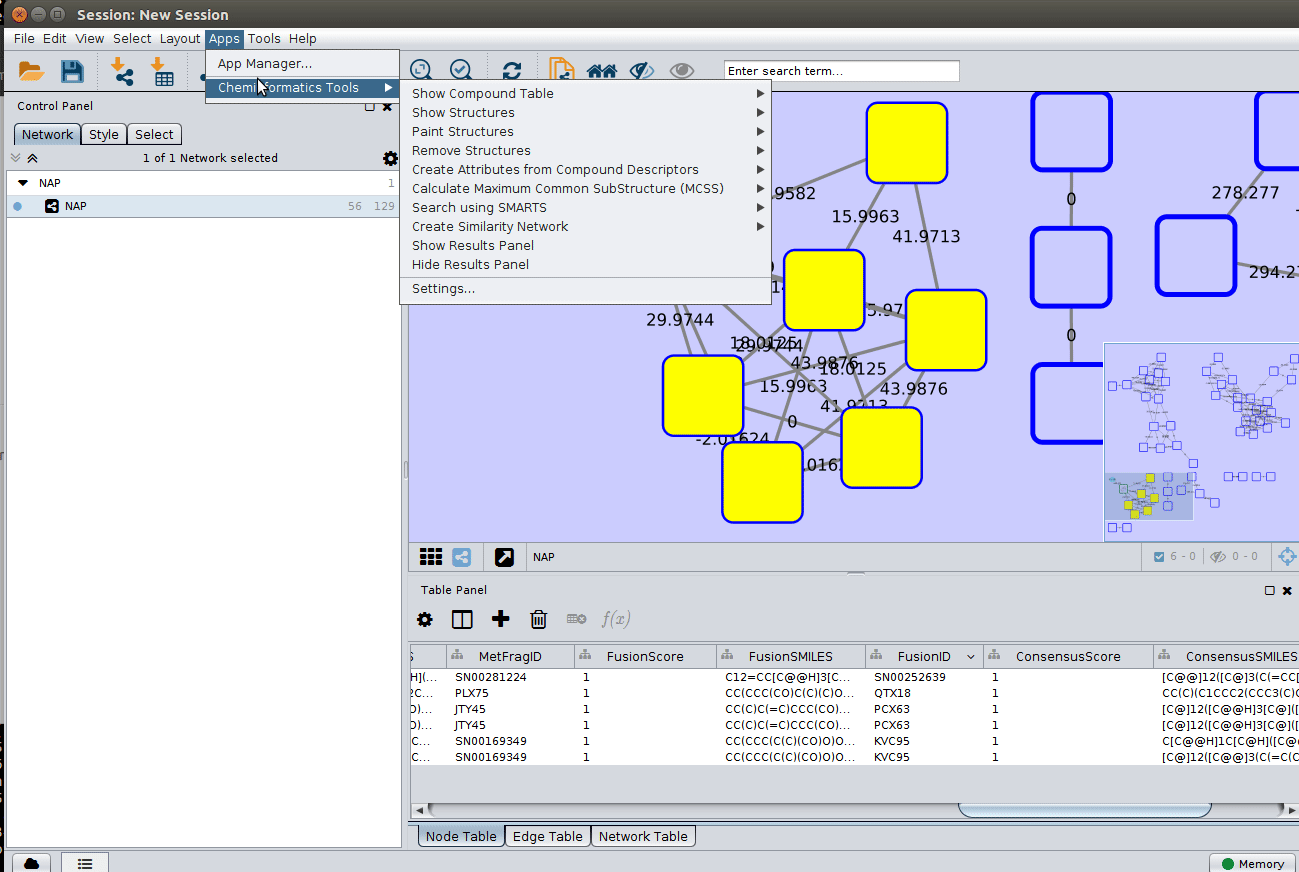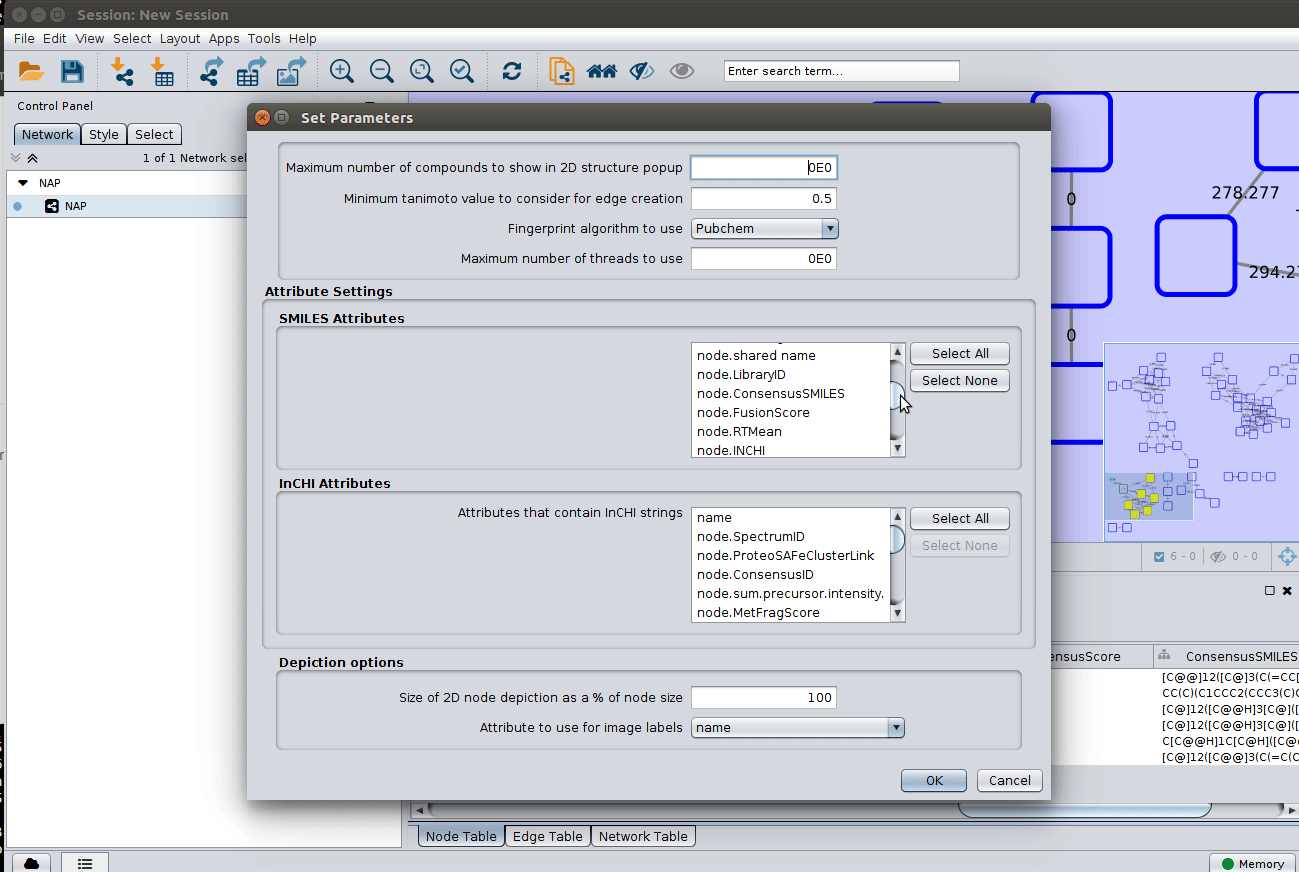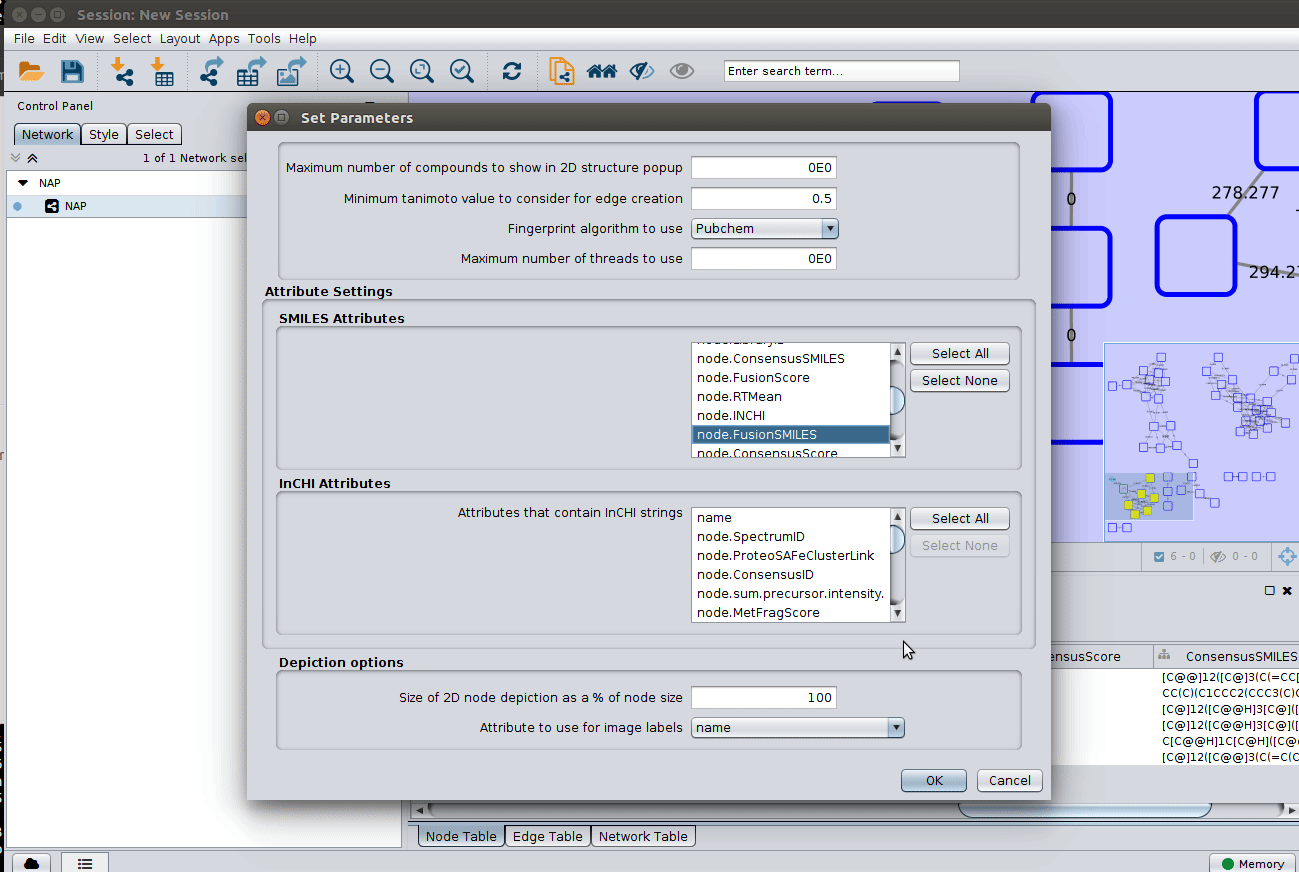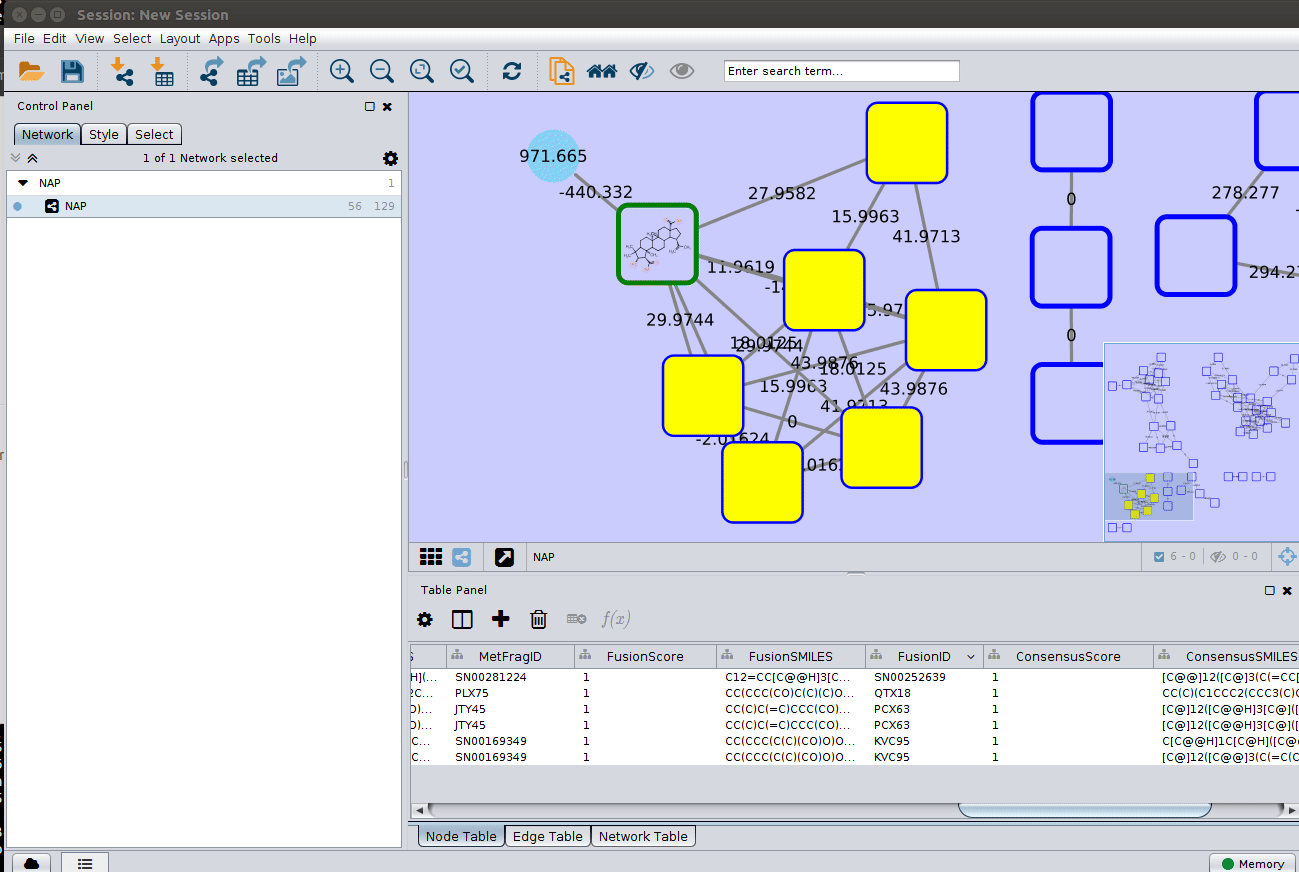
The 'structure_graph_alt.xgmml' file contains some pre-set elements to aid structure display. Nodes possessing a structure are empty squares. Node borders are either green (spectral library match) or blue (in silico prediction). In silico predictions can be a combination of MetFrag, Fusion and Consensus. Browsing the 'Table Panel' is possible to inspect which scoring method has structures available in the columns MetFrag/Fusion/ConsensusSMILES. To use one of these columns to display the structures we have first to change the properties of ChemViz, by doing:
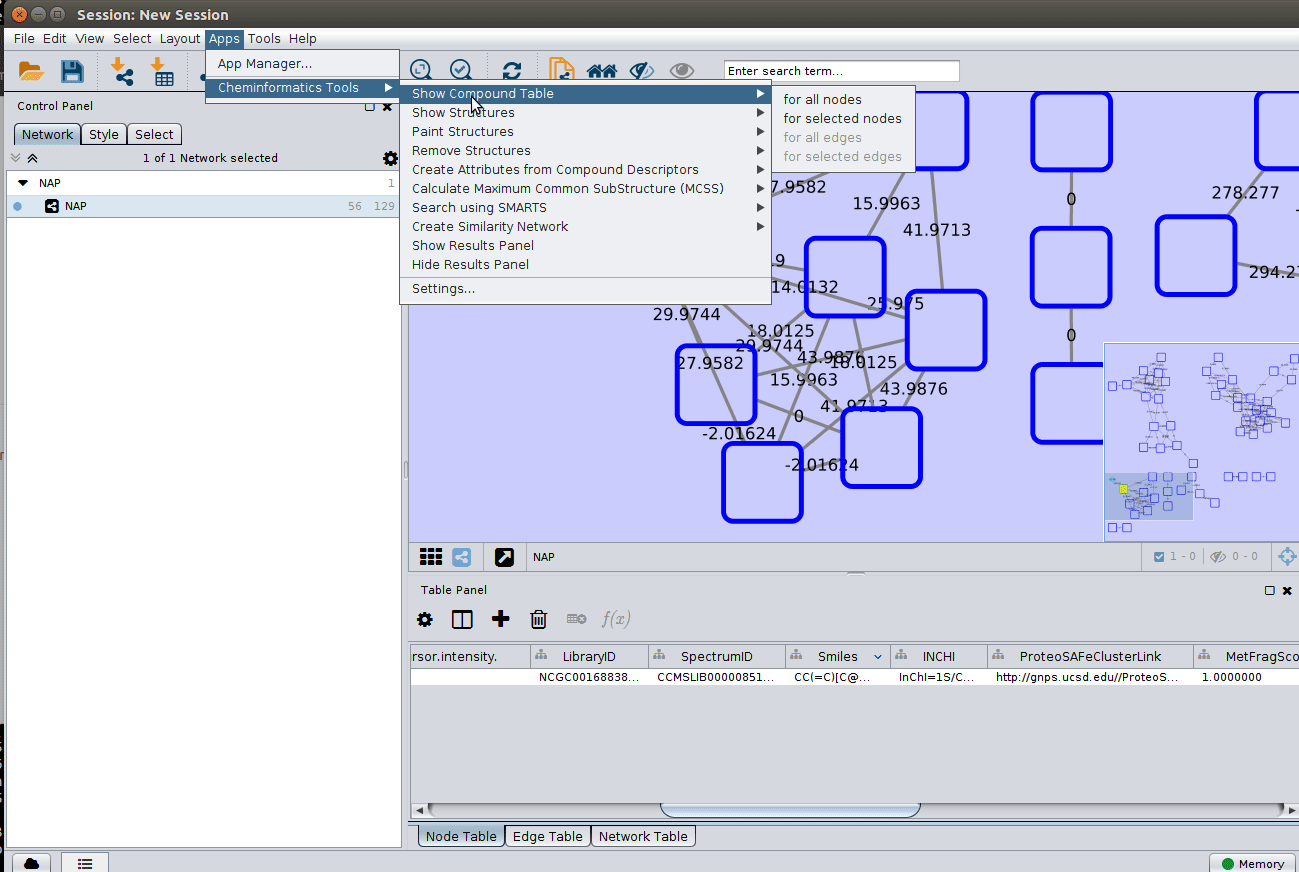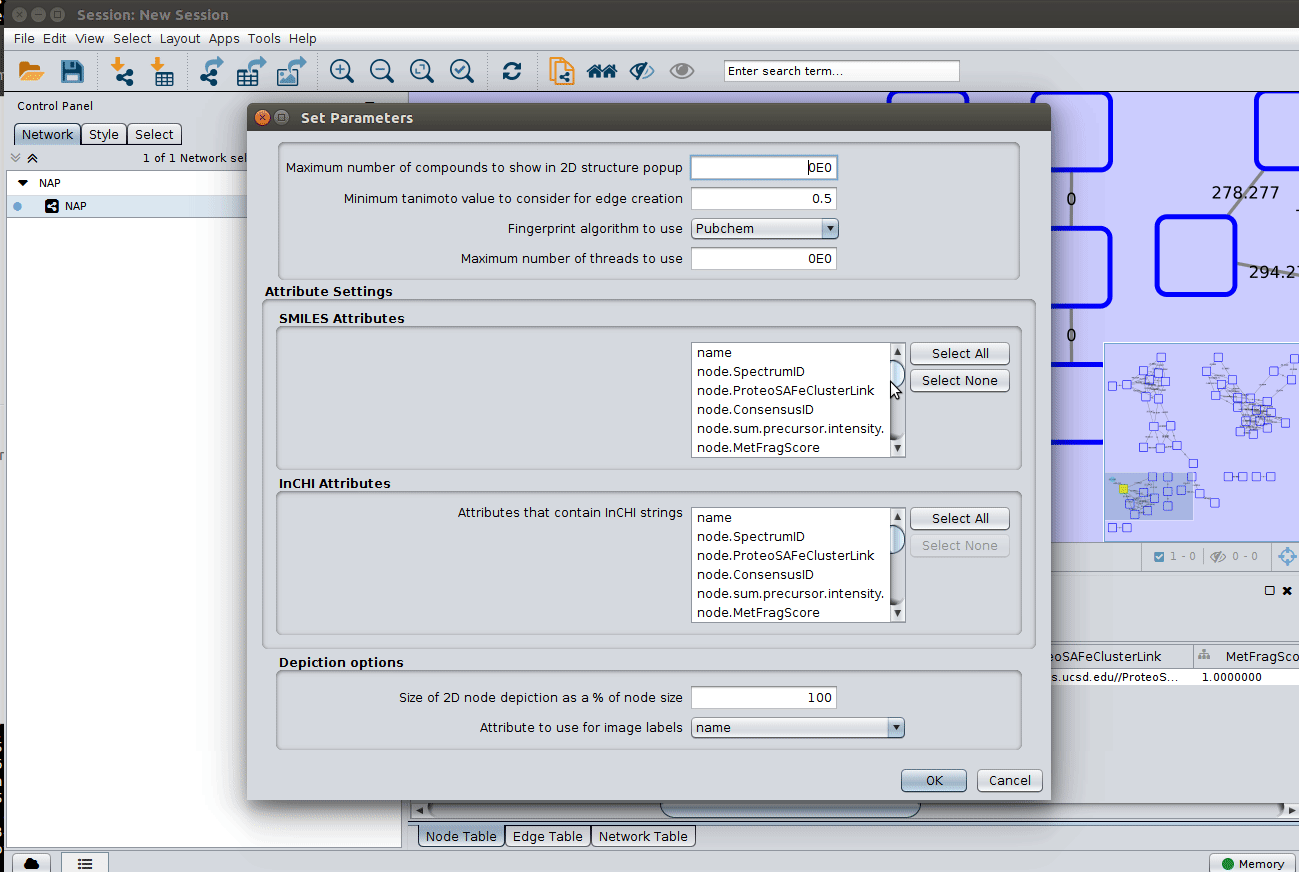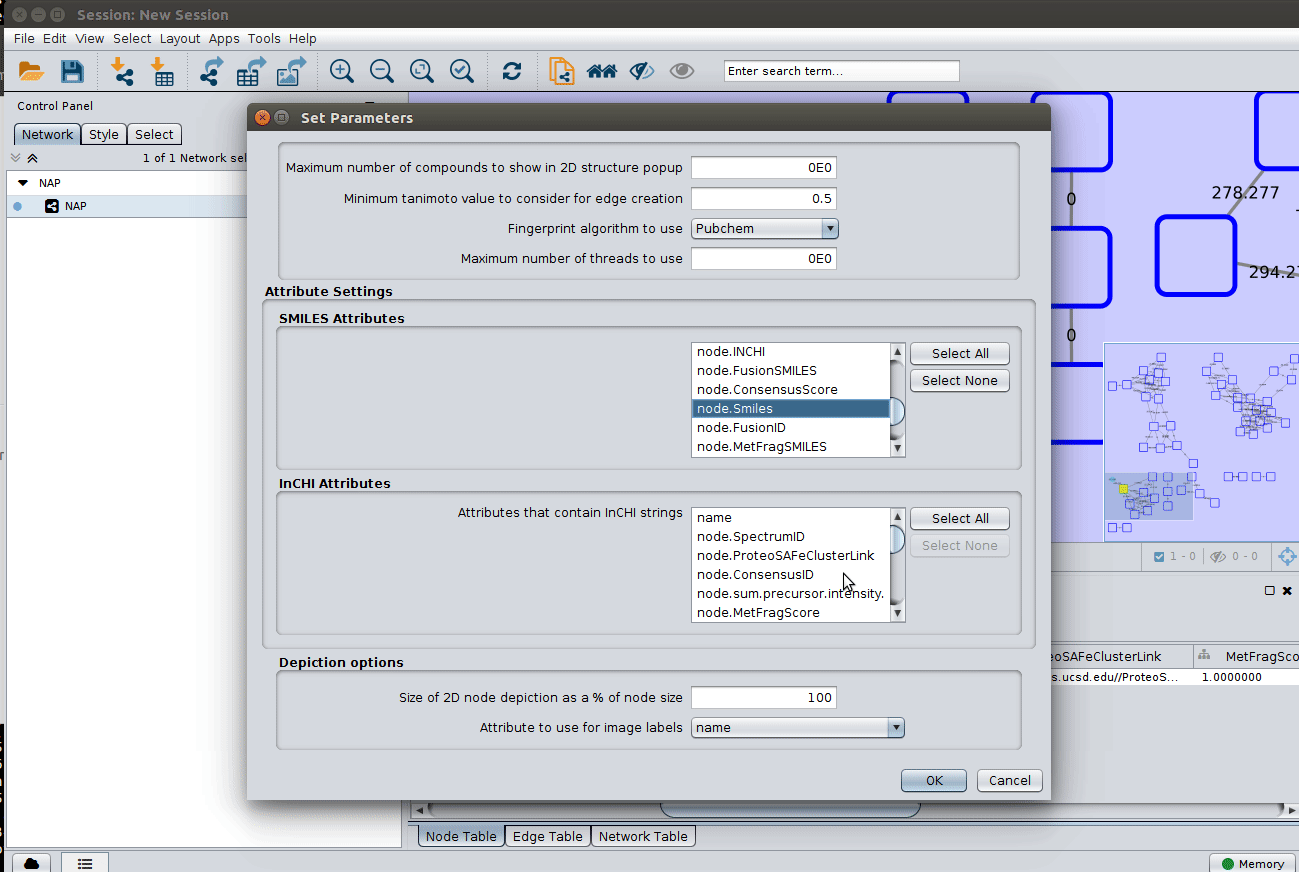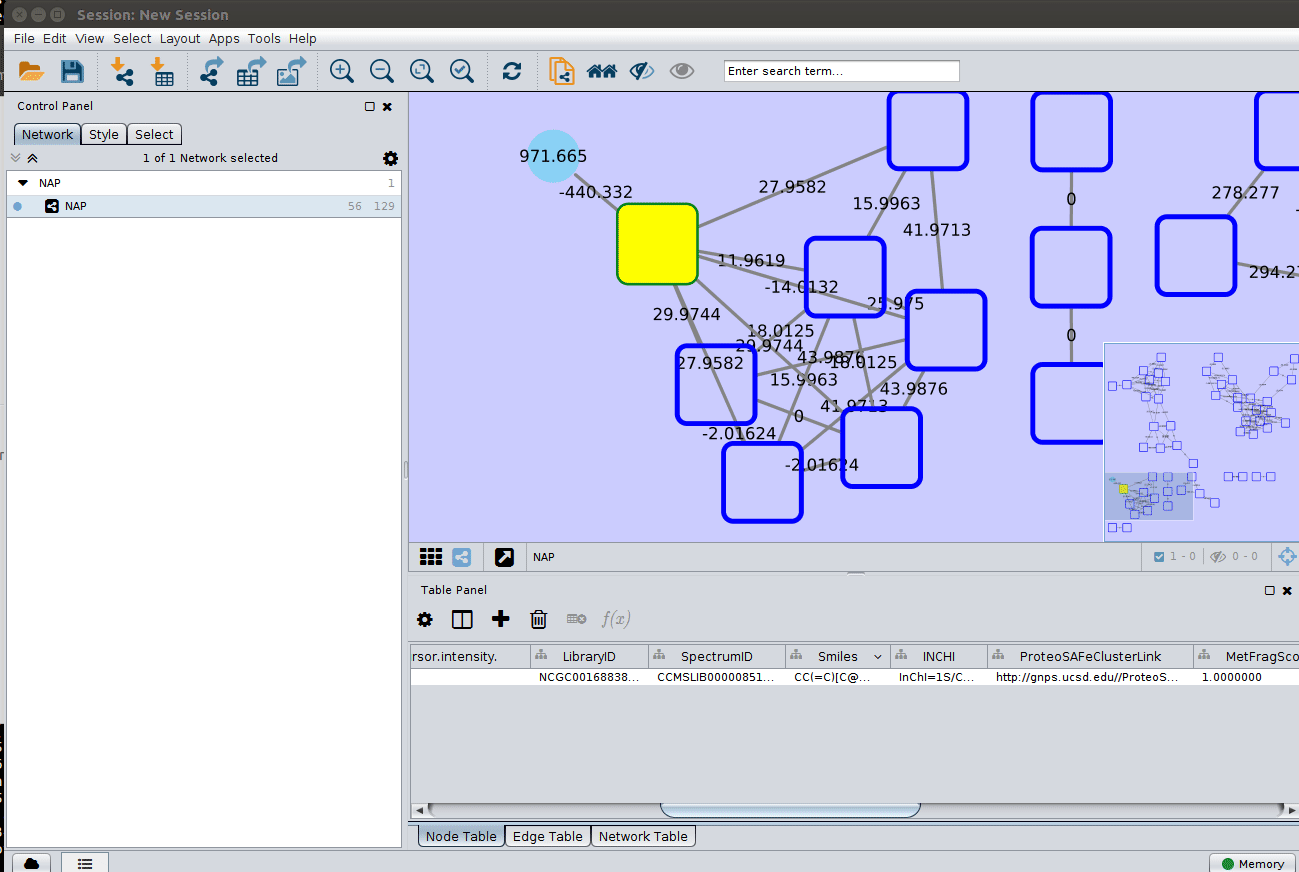
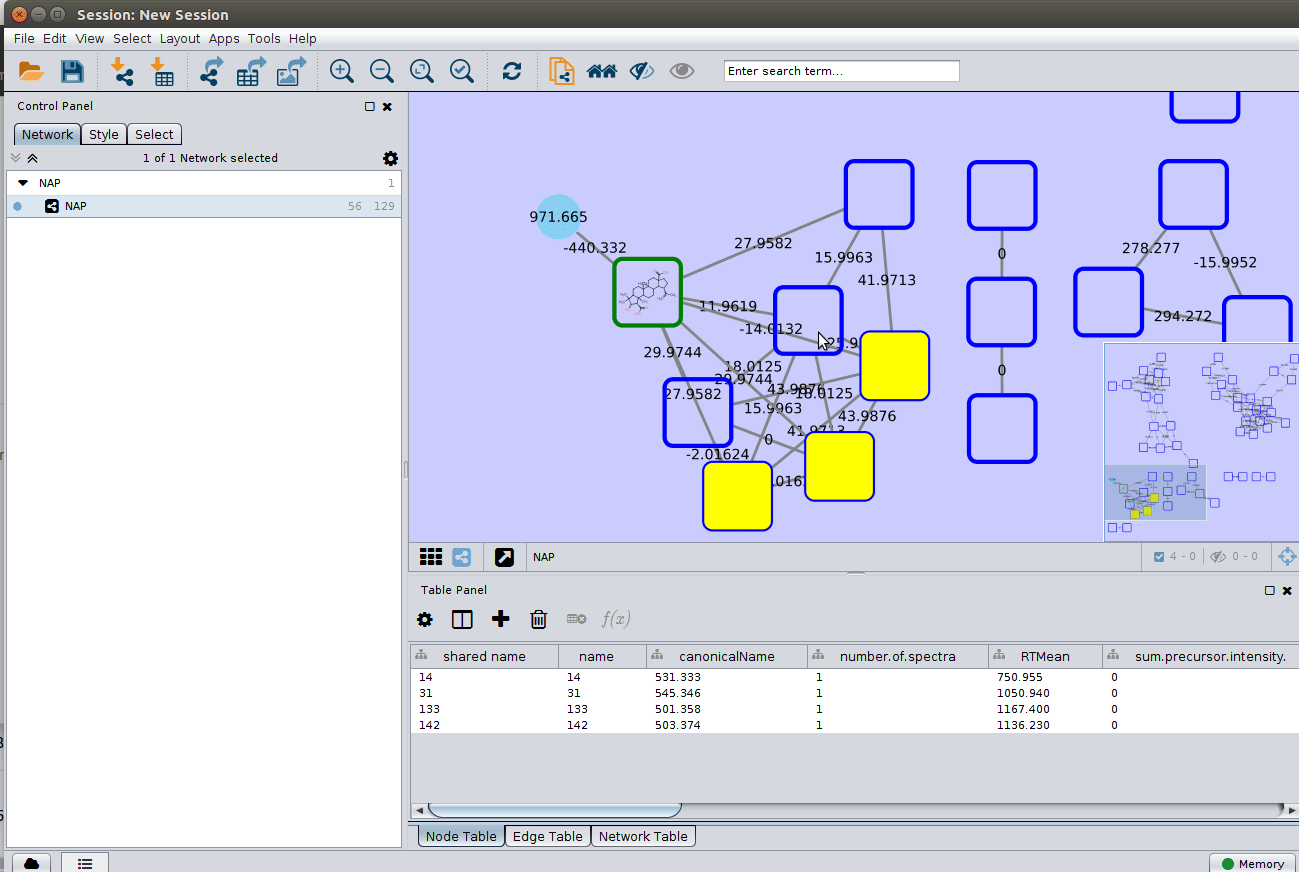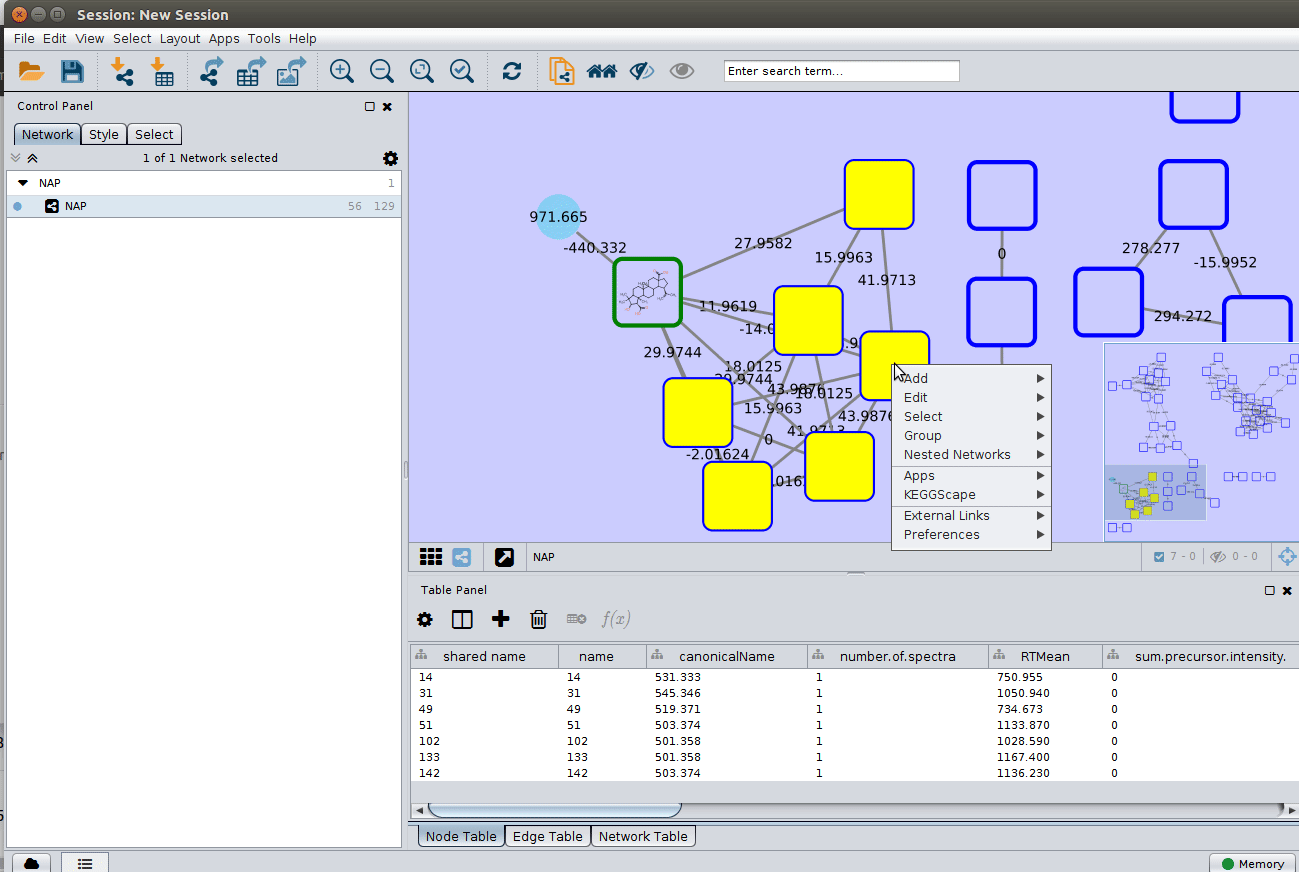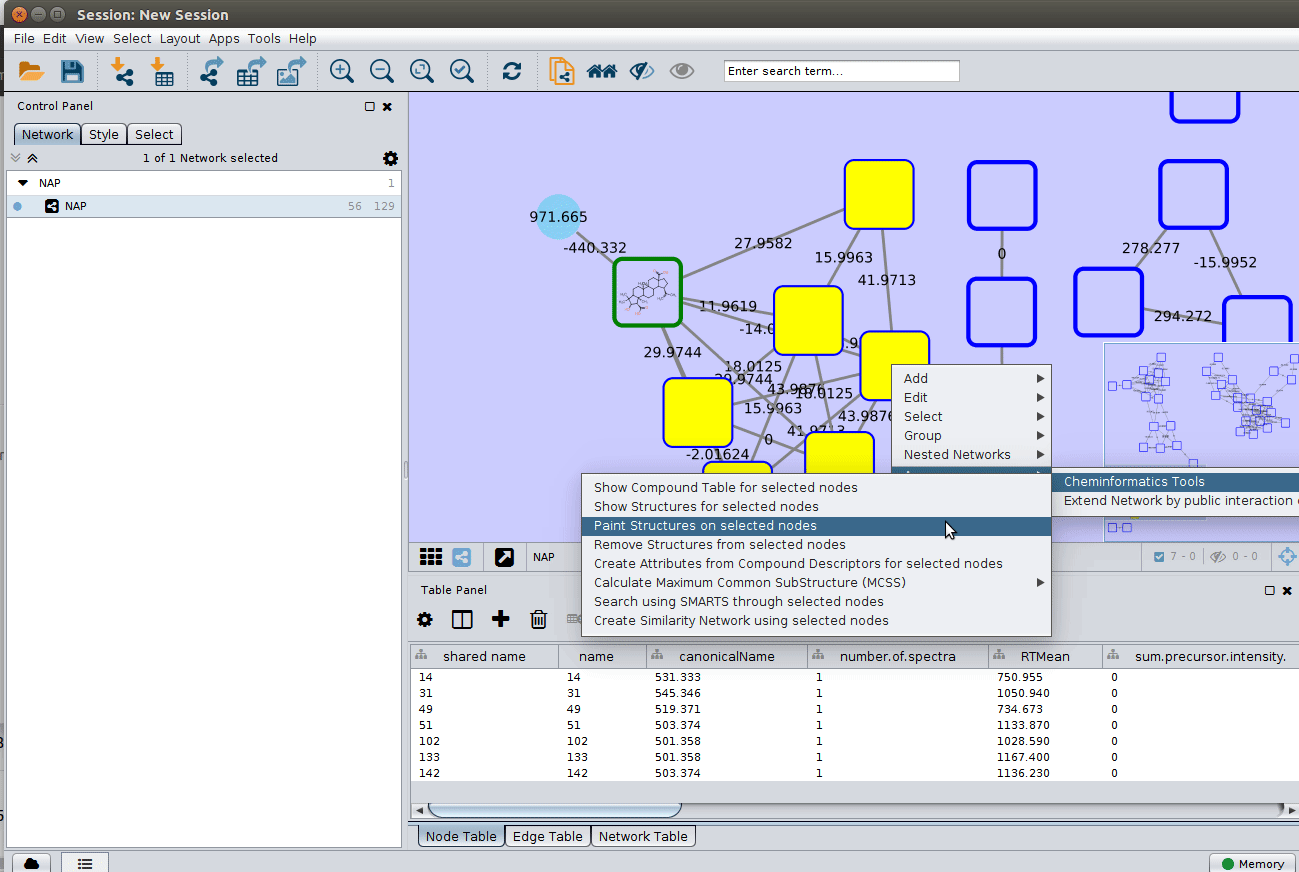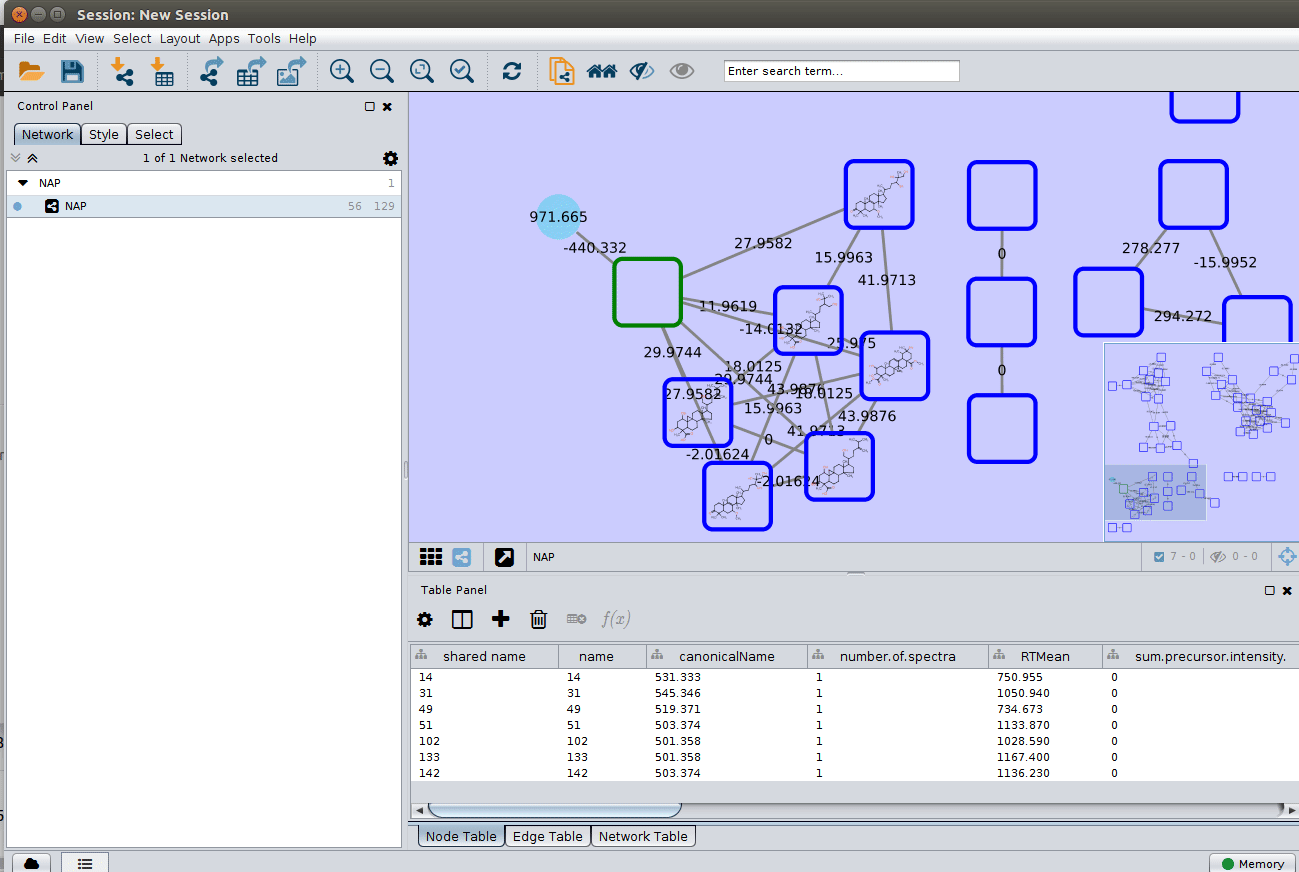
After setting the desired source column to display the structure one can just 'paint' the structure on the node:
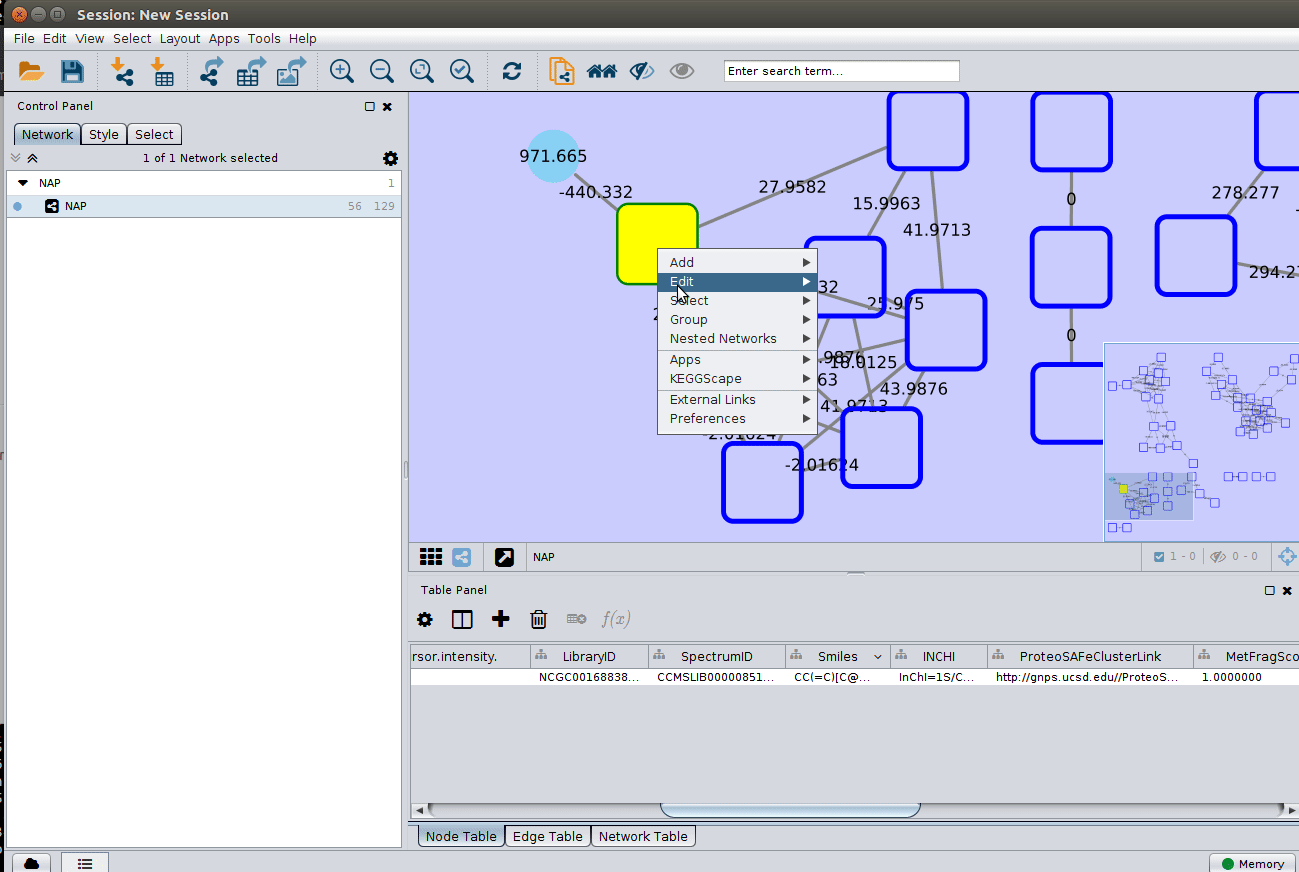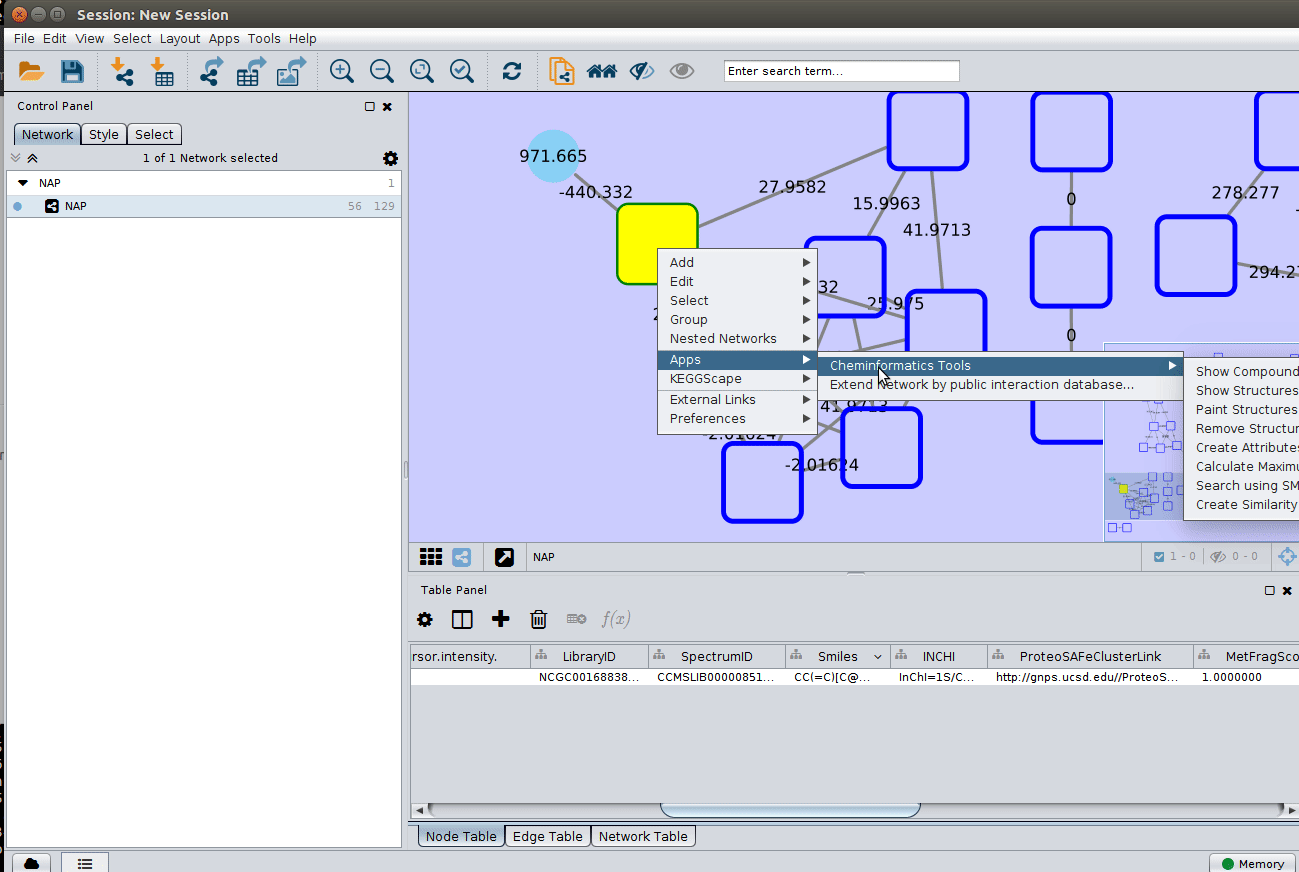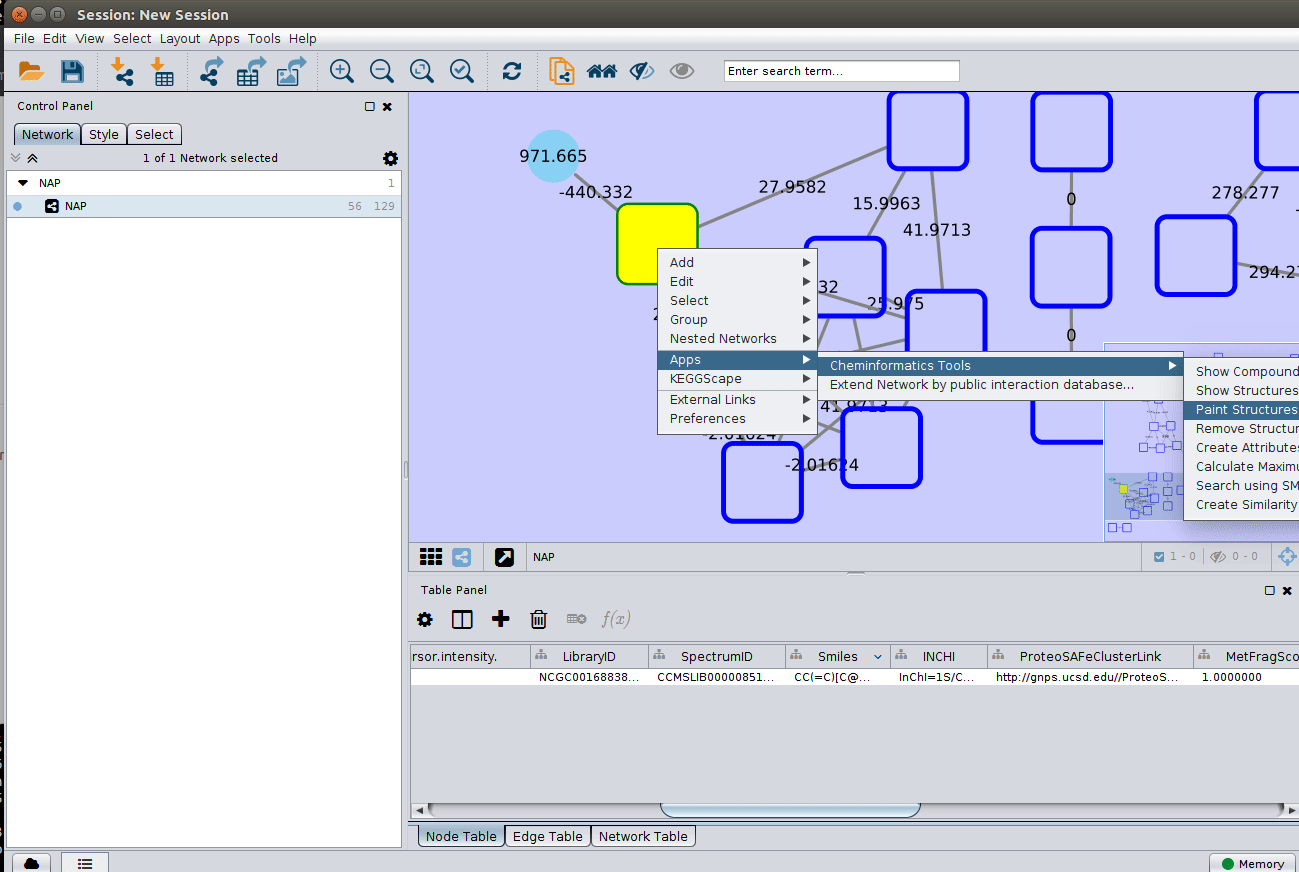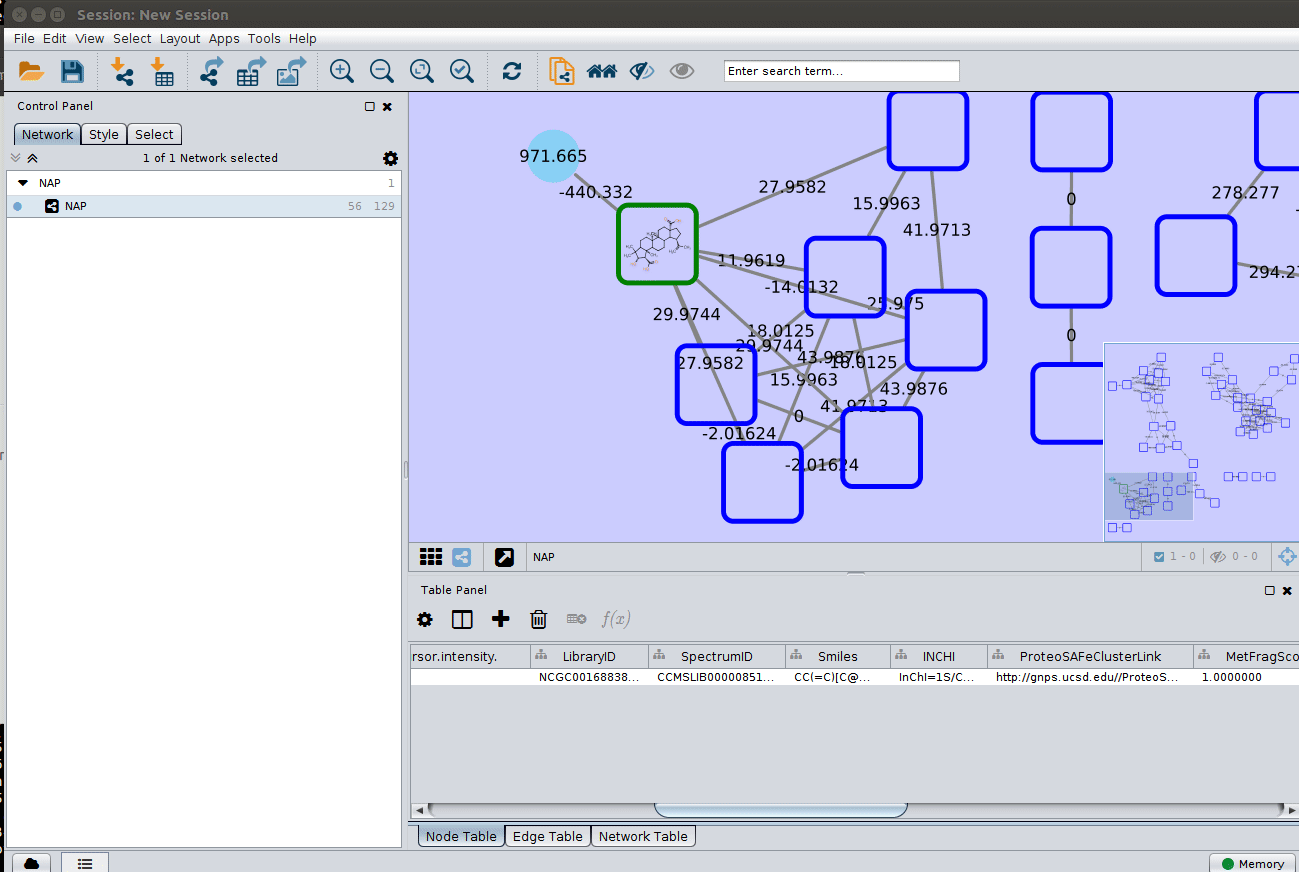
Change display properties and paint on multiple nodes¶
As we described in the publications below we have a decreasing order of confidence on structural prediction spectral library match > Fusion scoring > Consensus scoring > MetFrag scoring. To change for Fusion scoring structures you can do:
and paint the structures:
Display the list of candidates¶
As discussed in the Online Exploration section, the most correct structure may not be the first candidate. Therefore we can display the structures outputted from our initial parameters:
Citation¶
Contribute to the Documentation¶
- For informations/feature request, please open an "Issue" on the CCMS-UCSD/GNPSDocumentation GitHub repository.
- To contribute directly to the GNPS documentation, fork the CCMS-UCSD/GNPSDocumentation repository, and make a "Pull Request".
Page Contributors¶